The Database Abstraction Layer (DAL)
DAL introduction
py4web rely on a database abstraction layer (DAL), an API that maps Python objects into database objects such as queries, tables, and records. The DAL dynamically generates the SQL in real time using the specified dialect for the database back end, so that you do not have to write SQL code or learn different SQL dialects (the term SQL is used generically), and the application will be portable among different types of databases. The DAL choosen is a pure Python one called pyDAL. It was conceived in the web2py project but it’s a standard python module: you can use it in any Python context.
Note
What makes pyDAL different from most of the other DALs is the syntax: it maps records to python dictionaries, which is simpler and closer to SQL. Other famous frameworks instead strictly rely on an Object Relational Mapping (ORM) like the Django ORM or the SQL Alchemy ORM, that maps tables to Python classes and rows to Objects.
A little taste of pyDAL features:
Transactions
Aggregates
Inner & Outer Joins
Nested Selects
Note
An important difference between py4web and web2py is that only some few Field attributes are safe to modify in actions. See Thread safety and Field attributes for more info, and From web2py to py4web for a general list of differences.
Supported databases
A partial list of supported databases is show in the table below. Please check on the py4web/pyDAL web site and mailing list for more recent adapters.
Note
In any modern python distribution SQLite is actually built-in as a Python library. The SQLite driver (sqlite3) is also included: you don’t need to install it. Hence this is the most popular database for testing and development.
The Windows and the Mac binary distribution work out of the box with SQLite and PostgreSQL only. To use any other database back end, run a full py4web distribution and install the appropriate driver for the required back end. Once the proper driver is installed, start py4web and it will automatically find the driver.
Here is a list of the drivers py4web can use:
Database |
Drivers (source) |
|---|---|
SQLite |
sqlite3 or pysqlite2 or zxJDBC (on Jython) |
PostgreSQL |
psycopg2 or zxJDBC (on Jython) |
MySQL |
pymysql or MySQLdb |
Oracle |
cx_Oracle |
MSSQL |
pyodbc or pypyodbc |
FireBird |
kinterbasdb or fdb or pyodbc |
DB2 |
pyodbc |
Informix |
informixdb |
Ingres |
ingresdbi |
Cubrid |
cubriddb |
Sybase |
Sybase |
Teradata |
pyodbc |
SAPDB |
sapdb |
MongoDB |
pymongo |
IMAP |
imaplib |
Support of MongoDB is experimental. Google NoSQL is treated as a particular case. The Gotchas section at the end of this chapter has some more information about specific databases.
The DAL: a quick tour
py4web defines the following classes that make up the DAL:
- DAL
represents a database connection. For example:
db = DAL('sqlite://storage.sqlite')
- Table
represents a database table. You do not directly instantiate Table; instead,
DAL.define_tabledoes.db.define_table('mytable', Field('myfield'))
The most important methods of a Table are:
insert,truncate,drop, andimport_from_csv_file.- Field
represents a database field. It can be instantiated and passed as an argument to
DAL.define_table.- Rows
is the object returned by a database select. It can be thought of as a list of
Rowrows:rows = db(db.mytable.myfield != None).select()
- Row
contains field values:
for row in rows: print(row.myfield)
- Query
is an object that represents a SQL “where” clause:
myquery = (db.mytable.myfield != None) | (db.mytable.myfield > 'A')
- Set
is an object that represents a set of records. Its most important methods are
count,select,update, anddelete. For example:myset = db(myquery) rows = myset.select() myset.update(myfield='somevalue') myset.delete()
- Expression
is something like an
orderbyorgroupbyexpression. The Field class is derived from the Expression. Here is an example.myorder = db.mytable.myfield.upper() | db.mytable.id db().select(db.table.ALL, orderby=myorder)
Using the DAL “stand-alone”
pyDAL is an independent python package. As such, it can be used
without the web2py/py4web environment; you just need to install
it with pip. Then import the pydal module when needed:
>>> from pydal import DAL, Field
Note
Even if you can import modules directly from pydal, this is not
advisable from within py4web applications. Remember that py4web.DAL
is a fixture, pydal.DAL is not. In this context, the last command
should better be:
>>> from py4web import DAL, Field
Experiment with the py4web shell
You can also experiment with the pyDAL API using the py4web shell, that is available using the shell command option.
Warning
Mind that database changes may be persistent. So be careful and do NOT hesitate to create a new application for doing testing instead of tampering with an existing one. The only exception is the showcase db: in case of problems you can recreate it by simply deleting the database folder and restarting py4web. This will re-create the database with all the example data.
Note that most of the code snippets that contain the python prompt
>>> are also directly executable via a py4web shell.
This is a simple example, using the provided showcase app:
>>> from apps.showcase.examples.models import db
>>> db.tables()
['auth_user', 'auth_user_tag_groups', 'person', 'superhero', 'superpower', 'tag', 'thing', 'user_token', 'dummy']
>>> rows = db(db.superhero.name != None).select()
>>> rows.first()
<Row {'id': 1, 'tag': <Set ("tag"."superhero" = 1)>, 'name': 'Superman', 'real_identity': 1}>
You can also start by creating a connection from zero. For the sake of simplicity, you can use SQLite. Nothing in this discussion changes when you switch the back-end engine.
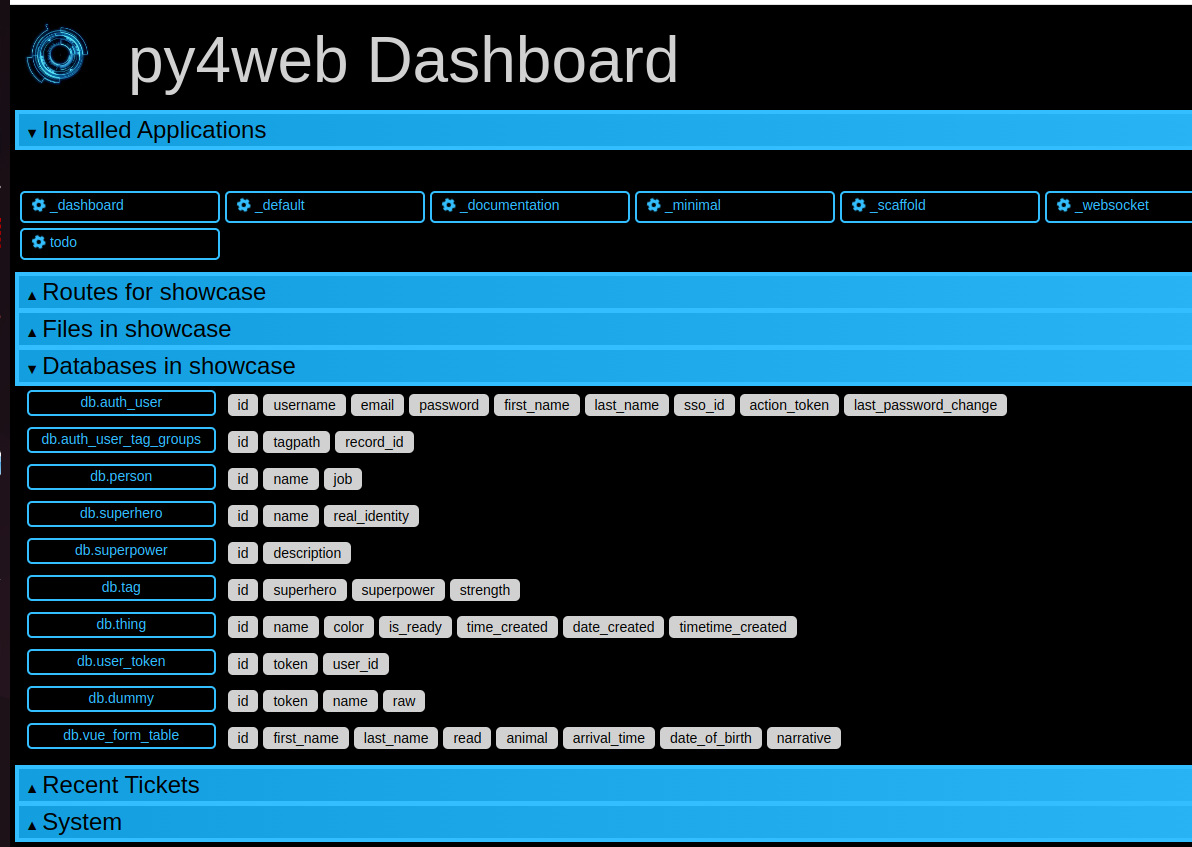
Using the dashboard app with databases
Generally you can use the dashboard app for viewing and modifying the databases of a particular app. However this is not bulletproof, so for security reason this by default is not applied to the showcase app. But if your installation is local (not exposed to public networks), you can enable it by simply adding to the file``apps/showcase/__init__.py`` the line:
from .examples.models import db
This allow you to look graphically inside the showcase application database:
DAL constructor
Basic use:
>>> db = DAL('sqlite://storage.sqlite')
The database is now connected and the connection is stored in the global
variable db.
At any time you can retrieve the connection string.
>>> db._uri
sqlite://storage.sqlite
and the database name
>>> db._dbname
sqlite
The connection string is called _uri because it is an instance of
a uniform resource identifier.
The DAL allows multiple connections with the same database or with different databases, even databases of different types. For now, we will assume the presence of a single database since this is the most common situation.
DAL signature
DAL(uri='sqlite://dummy.db',
pool_size=0,
folder=None,
db_codec='UTF-8',
check_reserved=None,
migrate=True,
fake_migrate=False,
migrate_enabled=True,
fake_migrate_all=False,
decode_credentials=False,
driver_args=None,
adapter_args=None,
attempts=5,
auto_import=False,
bigint_id=False,
debug=False,
lazy_tables=False,
db_uid=None,
do_connect=True,
after_connection=None,
tables=None,
ignore_field_case=True,
entity_quoting=False,
table_hash=None)
Connection strings (the uri parameter)
A connection with the database is established by creating an instance of the DAL object:
db = DAL('sqlite://storage.sqlite')
db is not a keyword; it is a local variable that stores the
connection object DAL. You are free to give it a different name. The
constructor of DAL requires a single argument, the connection
string. The connection string is the only py4web code that depends on a
specific back-end database. Here are examples of connection strings for
specific types of supported back-end databases (in all cases, we assume
the database is running from localhost on its default port and is named
“test”):
Database |
Connection string |
|---|---|
SQLite |
|
MySQL |
|
PostgreSQL |
|
MSSQL (legacy) |
|
MSSQL (>=2005) |
|
MSSQL (>=2012) |
|
FireBird |
|
Oracle |
|
DB2 |
|
Ingres |
|
Sybase |
|
Informix |
|
Teradata |
|
Cubrid |
|
SAPDB |
|
IMAP |
|
MongoDB |
|
Google/SQL |
|
Google/NoSQL |
|
Google/NoSQL/NDB |
|
in SQLite the database consists of a single file. If it does not exist, it is created. This file is locked every time it is accessed. In addition to the file ‘storage.sqlite’ that contains the data, there will be also a sql.log file plus one additional file called longhash_tablename.table for every table definition. The table definition files are used during migrations; in case of problems they could be deleted (they’ll be automatically recreated).
in the case of MySQL, PostgreSQL, MSSQL, FireBird, Oracle, DB2, Ingres and Informix the database “test” must be created outside py4web. Once the connection is established, py4web will create, alter, and drop tables appropriately.
in the MySQL connection string, the
?set_encoding=utf8mb4at the end sets the encoding to UTF-8 and avoids anInvalid utf8 character string:error on Unicode characters that consist of four bytes, as by default, MySQL can only handle Unicode characters that consist of one to three bytes.in the Google/NoSQL case the
+ndboption turns on NDB. NDB uses a Memcache buffer to read data that is accessed often. This is completely automatic and done at the datastore level, not at the py4web level.it is also possible to set the connection string to
None. In this case DAL will not connect to any back-end database, but the API can still be accessed for testing.
Some times you may also need to generate SQL as if you had a connection but without actually connecting to the database. This can be done with
db = DAL('...', do_connect=False)
In this case you will be able to call _select, _insert,
_update, and _delete to generate SQL but not call select,
insert, update, and delete; see Generating raw SQL
for details. In most of the cases you can use
do_connect=False even without having the required database drivers.
Notice that by default py4web uses utf8 character encoding for
databases. If you work with existing databases that behave differently,
you have to change it with the optional parameter db_codec like
db = DAL('...', db_codec='latin1')
Otherwise you’ll get UnicodeDecodeError tickets.
Connection pooling
A common argument of the DAL constructor is the pool_size; it
defaults to zero.
As it is rather slow to establish a new database connection for each request, py4web implements a mechanism for connection pooling. Once a connection is established and the page has been served and the transaction completed, the connection is not closed but goes into a pool. When the next request arrives, py4web tries to recycle a connection from the pool and use that for the new transaction. If there are no available connections in the pool, a new connection is established.
When py4web starts, the pool is always empty. The pool grows up to the
minimum between the value of pool_size and the max number of
concurrent requests. This means that if pool_size=10 but our server
never receives more than 5 concurrent requests, then the actual pool
size will only grow to 5. If pool_size=0 then connection pooling is
not used.
Connections in the pools are shared sequentially among threads, in the sense that they may be used by two different but not simultaneous threads. There is only one pool for each py4web process.
The pool_size parameter is ignored by SQLite and Google App Engine.
Connection pooling is ignored for SQLite, since it would not yield any
benefit.
Connection failures (attempts parameter)
If py4web fails to connect to the database it waits 1 second and by default tries again up to 5 times before declaring a failure. In case of connection pooling it is possible that a pooled connection that stays open but unused for some time is closed by the database end. Thanks to the retry feature py4web tries to re-establish these dropped connections. The number of attempts is set via the attempts parameter.
Lazy Tables
Setting lazy_tables = True provides a major performance boost (but
not with py4web). It means that table creation is deferred until the
table is actually referenced.
Warning
You should never use lazy tables in py4web. There is no advantage, no need, and possibly concurrency problems.
Model-less applications
Normally in py4web the code that define DAL tables lives in the file
models.py, hence it’s only executed at startup because it’s outside of actions.
However, it is possible to define DAL tables on demand inside actions. This is referred to as “model-less” development by the py4web community.
To use the “model-less” approach, you take responsibility for doing
all the housekeeping tasks. You call the table definitions when you
need them, and provide database connection passed as parameter.
Also, remember maintainability: other py4web developers expect to find
database definitions in the models.py file.
Replicated databases
The first argument of DAL(...) can be a list of URIs. In this case
py4web tries to connect to each of them. The main purpose for this is to
deal with multiple database servers and distribute the workload among
them. Here is a typical use case:
db = DAL(['mysql://...1', 'mysql://...2', 'mysql://...3'])
In this case the DAL tries to connect to the first and, on failure, it will try the second and the third. This can also be used to distribute load in a database master-slave configuration.
Reserved keywords
check_reserved tells the constructor to check table names and column
names against reserved SQL keywords in target back-end databases.
check_reserved defaults to None.
This is a list of strings that contain the database back-end adapter names.
The adapter name is the same as used in the DAL connection string. So if you want to check against PostgreSQL and MSSQL then your db connection would look as follows:
db = DAL('sqlite://storage.sqlite', check_reserved=['postgres', 'mssql'])
The DAL will scan the keywords in the same order as of the list.
There are two extra options “all” and “common”. If you specify all, it
will check against all known SQL keywords. If you specify common, it
will only check against common SQL keywords such as SELECT,
INSERT, UPDATE, etc.
For supported back ends you may also specify if you would like to check
against the non-reserved SQL keywords as well. In this case you would
append _nonreserved to the name. For example:
check_reserved=['postgres', 'postgres_nonreserved']
The following database backends support reserved words checking.
Database |
check_reserved |
|---|---|
PostgreSQL |
|
MySQL |
|
FireBird |
|
MSSQL |
|
Oracle |
|
Database quoting and case settings
Quoting of SQL entities are enabled by default in DAL, that is:
entity_quoting = True
This way identifiers are automatically quoted in SQL generated by DAL. At SQL level keywords and unquoted identifiers are case insensitive, thus quoting an SQL identifier makes it case sensitive.
Notice that unquoted identifiers should always be folded to lower case by the back-end engine according to SQL standard but not all engines are compliant with this (for example PostgreSQL default folding is upper case).
By default DAL ignores field case too, to change this use:
ignore_field_case = False
To be sure of using the same names in python and in the DB schema, you must arrange for both settings above. Here is an example:
db = DAL(ignore_field_case=False)
db.define_table('table1', Field('column'), Field('COLUMN'))
query = db.table1.COLUMN != db.table1.column
Making a secure connection
Sometimes it is necessary (and advised) to connect to your database using secure connection, especially if your database is not on the same server as your application. In this case you need to pass additional parameters to the database driver. You should refer to database driver documentation for details.
For PostgreSQL with psycopg2 it should look like this:
DAL('postgres://user_name:user_password@server_addr/db_name',
driver_args={'sslmode': 'require', 'sslrootcert': 'root.crt',
'sslcert': 'postgresql.crt', 'sslkey': 'postgresql.key'})
where parameters sslrootcert, sslcert and sslkey should
contain the full path to the files. You should refer to PostgreSQL
documentation on how to configure PostgreSQL server to accept secure
connections.
Other DAL constructor parameters
Database folder location
folder sets the place where migration files will be created (see
Migrations for details). By default it’s automatically set within py4web on the same
folder of the database itself, but you have to specify it when using DAL outside py4web.
Note that for SQLite databases it’s normally necessary, otherwise you’ll implicitly choose an in memory database (where folder and migrations don’t have any sense). So these constructors have the same meaning:
db = DAL('sqlite://storage.sqlite') # folder parameter not specified
db = DAL('sqlite:memory') # in memory database
Default migration settings
The DAL constructor migration settings are booleans affecting defaults and global behaviour (again, see Migrations for details)
migrate = True sets default migrate behavior for all tables
fake_migrate = False sets default fake_migrate behavior for all
tables
migrate_enabled = True If set to False disables ALL migrations
fake_migrate_all = False If set to True fake migrates ALL tables
commit and rollback
The insert, truncate, delete, and update operations aren’t actually committed until py4web issues the commit command. The create and drop operations may be executed immediately, depending on the database engine.
If you pass db in an action.uses decorator, you don’t need to call
commit in the controller, it is automatically done for you (also, if you use
authenticated or unauthenticated decorator.)
Tip
always add db in an action.uses decorator (or use the
authenticated or unauthenticated decorator).
Otherwise you have to add db.commit() in every define_table and
in every table activities: insert(), update(), delete()
So in actions there is normally no need to ever call
commit or rollback explicitly in py4web unless you need more
granular control.
But if you executed commands via the shell, you are required to manually commit:
>>> db.commit()
To check it let’s insert a new record:
>>> db.person.insert(name="Bob")
2
and roll back, i.e., ignore all operations since the last commit:
>>> db.rollback()
If you now insert again, the counter will again be set to 2, since the previous insert was rolled back.
>>> db.person.insert(name="Bob")
2
Code in models, views and controllers is enclosed in py4web code that looks like this (pseudo code):
try:
execute models, controller function and view
except:
rollback all connections
log the traceback
send a ticket to the visitor
else:
commit all connections
save cookies, sessions and return the page
Table constructor
Tables are defined in the DAL via define_table.
define_table signature
The signature for define_table method is:
define_table(tablename, *fields, **kwargs)
It accepts a mandatory table name and an optional number of Field
instances (even none). You can also pass a Table (or subclass)
object instead of a Field one, this clones and adds all the fields
(but the “id”) to the defining table. Other optional keyword args are:
rname, redefine, common_filter, fake_migrate,
fields, format, migrate, on_define, plural,
polymodel, primarykey, sequence_name, singular,
table_class, and trigger_name, which are discussed below.
For example:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
It defines, stores and returns a Table object called “person”
containing a field (column) “name”. This object can also be accessed via
db.person, so you do not need to catch the value returned by
define_table.
id: Notes about the primary key
Do not declare a field called “id”, because one is created by py4web anyway. Every table has a field called “id” by default. It is an auto-increment integer field (usually starting at 1) used for cross-reference and for making every record unique, so “id” is a primary key. (Note: the id counter starting at 1 is back-end specific. For example, this does not apply to the Google App Engine NoSQL.)
Optionally you can define a field of type='id' and py4web will use
this field as auto-increment id field. This is not recommended except
when accessing legacy database tables which have a primary key under a
different name. With some limitation, you can also use different primary
keys using the primarykey parameter.
plural and singular
As pyDAL is a general DAL, it includes plural and singular attributes to refer to the table names so that external elements can use the proper name for a table.
redefine
Tables can be defined only once but you can force py4web to redefine an existing table:
db.define_table('person', Field('name'))
db.define_table('person', Field('name'), redefine=True)
The redefinition may trigger a migration if table definition changes.
format: Record representation
It is optional but recommended to specify a format representation for
records with the format parameter.
db.define_table('person', Field('name'), format='%(name)s')
or
db.define_table('person', Field('name'), format='%(name)s %(id)s')
or even more complex ones using a function:
db.define_table('person', Field('name'),
format=lambda r: r.name or 'anonymous')
The format attribute will be used for two purposes:
To represent referenced records in select/option drop-downs.
To set the
db.othertable.otherfield.representattribute for all fields referencing this table. This means that theFormconstructor will not show references by id but will use the preferred format representation instead.
rname: Real name
rname sets a database backend name for the table. This makes the
py4web table name an alias, and rname is the real name used when
constructing the query for the backend. To illustrate just one use,
rname can be used to provide MSSQL fully qualified table names
accessing tables belonging to other databases on the server:
rname = 'db1.dbo.table1'
primarykey: Support for legacy tables
primarykey helps support legacy tables with existing primary keys,
even multi-part. See Legacy databases and keyed tables.
migrate, fake_migrate
migrate sets migration options for the table. Refer to
Migrations for details.
table_class
If you define your own table class as a sub-class of pydal.objects.Table, you can provide it here; this allows you to extend and override methods. Example:
from pydal.objects import Table
class MyTable(Table):
...
db.define_table(..., table_class=MyTable)
sequence_name
The name of a custom table sequence (if supported by the database). Can create a SEQUENCE (starting at 1 and incrementing by 1) or use this for legacy tables with custom sequences.
Note that when necessary, py4web will create sequences automatically by default.
trigger_name
Relates to sequence_name. Relevant for some backends which do not
support auto-increment numeric fields.
polymodel
For use with Google App Engine.
on_define
on_define is a callback triggered when a lazy_table is instantiated,
although it is called anyway if the table is not lazy. This allows
dynamic changes to the table without losing the advantages of delayed
instantiation.
Example:
db = DAL(lazy_tables=True)
db.define_table('person',
Field('name'),
Field('age', 'integer'),
on_define=lambda table: [
table.name.set_attributes(requires=IS_NOT_EMPTY(), default=''),
table.age.set_attributes(requires=IS_INT_IN_RANGE(0, 120), default=30) ])
Note this example shows how to use on_define but it is not actually
necessary. The simple requires values could be added to the Field
definitions and the table would still be lazy. However, requires
which take a Set object as the first argument, such as IS_IN_DB, will
make a query like db.sometable.somefield == some_value which would
cause sometable to be defined early. This is the situation saved by
on_define.
Adding attributes to fields and tables
If you need to add custom attributes to fields, you can simply do this:
db.table.field.extra = {}
“extra” is not a keyword; it’s a custom attribute now attached to the field object. You can do it with tables too but they must be preceded by an underscore to avoid naming conflicts with fields:
db.table._extra = {}
Legacy databases and keyed tables
py4web can connect to legacy databases under some conditions.
The easiest way is when these conditions are met:
Each table must have a unique auto-increment integer field called “id”.
Records must be referenced exclusively using the “id” field.
When accessing an existing table, i.e., a table not created by py4web in
the current application, always set migrate=False.
If the legacy table has an auto-increment integer field but it is not
called “id”, py4web can still access it but the table definition must
declare the auto-increment field with ‘id’ type (that is using
Field('...', 'id')).
Finally if the legacy table uses a primary key that is not an auto-increment id field it is possible to use a “keyed table”, for example:
db.define_table('account',
Field('accnum', 'integer'),
Field('acctype'),
Field('accdesc'),
primarykey=['accnum', 'acctype'],
migrate=False)
primarykeyis a list of the field names that make up the primary key.All primarykey fields have a
NOT NULLset even if not specified.Keyed tables can only reference other keyed tables.
Referencing fields must use the
reference tablename.fieldnameformat.The
update_recordfunction is not available for Rows of keyed tables.
Currently keyed tables are only supported for DB2, MSSQL, Ingres and Informix, but others engines will be added.
At the time of writing, we cannot guarantee that the primarykey
attribute works with every existing legacy table and every supported
database backend. For simplicity, we recommend, if possible, creating a
database view that has an auto-increment id field.
Field constructor
These are the default values of a Field constructor:
Field(fieldname, type='string', length=None, default=DEFAULT,
required=False, requires=DEFAULT,
ondelete='CASCADE', notnull=False, unique=False,
uploadfield=True, widget=None, label=None, comment=None,
writable=True, readable=True, searchable=True, listable=True,
update=None, authorize=None, autodelete=False, represent=None,
uploadfolder=None, uploadseparate=None, uploadfs=None,
compute=None, filter_in=None, filter_out=None,
custom_qualifier=None, map_none=None, rname=None)
where DEFAULT is a special value used to allow the value None for a parameter.
Not all of them are relevant for every field. length is relevant
only for fields of type “string”. uploadfield, authorize, and
autodelete are relevant only for fields of type “upload”.
ondelete is relevant only for fields of type “reference” and
“upload”.
lengthsets the maximum length of a “string”, “password” or “upload” field. Iflengthis not specified a default value is used but the default value is not guaranteed to be backward compatible. To avoid unwanted migrations on upgrades, we recommend that you always specify the length for string, password and upload fields.defaultsets the default value for the field. The default value is used when performing an insert if a value is not explicitly specified. It is also used to pre-populate forms built from the table usingForm. Note, rather than being a fixed value, the default can instead be a function (including a lambda function) that returns a value of the appropriate type for the field. In that case, the function is called once for each record inserted, even when multiple records are inserted in a single transaction.requiredtells the DAL that no insert should be allowed on this table if a value for this field is not explicitly specified.requiresis a validator or a list of validators. This is not used by the DAL, but instead it is used byForm(this will be explained better on the Forms chapter). The default validators for the given types are shown in the next section Field types and validators.Note
while
requires=...is enforced at the level of forms,required=Trueis enforced at the level of the DAL (insert). In addition,notnull,uniqueandondeleteare enforced at the level of the database. While they sometimes may seem redundant, it is important to maintain the distinction when programming with the DAL.rnameprovides the field with a “real name”, a name for the field known to the database adapter; when the field is used, it is the rname value which is sent to the database. The py4web name for the field is then effectively an alias.ondeletetranslates into the “ON DELETE” SQL statement. By default it is set to “CASCADE”. This tells the database that when it deletes a record, it should also delete all records that refer to it. To disable this feature, setondeleteto “NO ACTION” or “SET NULL”.notnull=Truetranslates into the “NOT NULL” SQL statement. It prevents the database from inserting null values for the field.unique=Truetranslates into the “UNIQUE” SQL statement and it makes sure that values of this field are unique within the table. It is enforced at the database level.uploadfieldapplies only to fields of type “upload”. A field of type “upload” stores the name of a file saved somewhere else, by default on the filesystem under the application “uploads/” folder. Ifuploadfieldis set to True, then the file is stored in a blob field within the same table and the value ofuploadfieldis the name of the blob field. This will be discussed in more detail later in More on uploads.uploadfoldermust be set to a location where to store uploaded files. The scaffolding app defines a foldersettings.UPLOAD_FOLDERwhich points toapps/{app_name}/uploadsso you can set, for example,Field(... uploadfolder=settings.UPLOAD_FOLDER).uploadseparateif set to True will upload files under different subfolders of the uploadfolder folder. This is optimized to avoid too many files under the same folder/subfolder. ATTENTION: You cannot change the value ofuploadseparatefrom True to False without breaking links to existing uploads. pydal either uses the separate subfolders or it does not. Changing the behavior after files have been uploaded will prevent pydal from being able to retrieve those files. If this happens it is possible to move files and fix the problem but this is not described here.uploadfsallows you specify a different file system where to upload files, including an Amazon S3 storage or a remote SFTP storage.
You need to have PyFileSystem installed for this to work.
uploadfsmust point to PyFileSystem.
autodeletedetermines if the corresponding uploaded file should be deleted when the record referencing the file is deleted. For “upload” fields only. However, records deleted by the database itself due to a CASCADE operation will not trigger py4web’s autodelete.labelis a string (or a helper or something that can be serialized to a string that contains the label to be used for this field in auto-generated forms.) that contains a comment associated with this field, and will be displayed to the right of the input field in the autogenerated forms.writabledeclares whether a field is writable in forms.readabledeclares whether a field is readable in forms. If a field is neither readable nor writable, it will not be displayed in create and update forms.updatecontains the default value for this field when the record is updated.computeis an optional function. If a record is inserted or updated, the compute function will be executed and the field will be populated with the function result. The record is passed to the compute function as adict, and the dict will not include the current value of that, or any other compute field.authorizecan be used to require access control on the corresponding field, for “upload” fields only. It will be discussed more in detail in the context of Authentication and Authorization.widgetDo NOT use the widget parameter in py4web for a Field definition. (This was a feature of web2py and is not to be used in py4web) See Widgets later.representcan be None or can point to a function that takes a field value and returns an alternate representation for the field value.
Thread safety and Field attributes
Even though py4web and web2py use the same pyDAL, there is an important difference
which stems from the core architecture of py4web.
In py4web only the following Field attributes can be changed inside an action:
readablewritabledefaultfilter_infilter_outlabelupdaterequireswidgetrepresent
These are reset to their original values before each action is called.
All other Field, DAL, and Table attributes are global and non-thread-safe.
This limitation exists because py4web executes table definitions only at startup, unlike web2py which re-defines tables on each request. This makes py4web a lot faster than web2py, but you need to be careful as modifying non-thread-safe attributes in actions can cause race conditions and bugs.
Field types and validators
Type |
Default validators |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Decimal requires and returns values as Decimal objects, as defined
in the Python decimal module. SQLite does not handle the decimal
type so internally we treat it as a double. The (n,m) are the number
of digits in total and the number of digits after the decimal point
respectively.
The big-id and, big-reference are only supported by some of the
database engines and are experimental. They are not normally used as
field types unless for legacy tables, however, the DAL constructor has a
bigint_id argument that when set to True makes the id fields
and reference fields big-id and big-reference respectively.
The list:<type> fields are special because they are designed to take
advantage of certain denormalization features on NoSQL (in the case of
Google App Engine NoSQL, the field types ListProperty and
StringListProperty) and back-port them all the other supported
relational databases. On relational databases lists are stored as a
text field. The items are separated by a | and each | in
string item is escaped as a ||. They are discussed in
list:<type> and contains.
The json field type is pretty much explanatory. It can store any
JSON serializable object. It is designed to work specifically for
MongoDB and backported to the other database adapters for portability.
blob fields are also special. By default, binary data is encoded in
base64 before being stored into the actual database field, and it is
decoded when extracted. This has the negative effect of using 33% more
storage space than necessary in blob fields, but has the advantage of
making the communication independent of the back-end specific escaping
conventions.
Run-time field and table modification
Most attributes of fields and tables can be modified after they are defined:
>>> db.define_table('person', Field('name', default=''), format='%(name)s')
<Table person (id, name)>
>>> db.person._format = '%(name)s/%(id)s'
>>> db.person.name.default = 'anonymous'
notice that attributes of tables are usually prefixed by an underscore to avoid conflict with possible field names.
You can list the tables that have been defined for a given database connection:
>>> db.tables
['person']
You can query for the type of a table:
>>> type(db.person)
<class 'pydal.objects.Table'>
You can access a table using different syntaxes:
>>> db.person is db['person']
True
You can also list the fields that have been defined for a given table:
>>> db.person.fields
['id', 'name']
Similarly you can access fields from their name in multiple equivalent ways:
>>> type(db.person.name)
<class 'pydal.objects.Field'>
>>> db.person.name is db.person['name']
True
Given a field, you can access the attributes set in its definition:
>>> db.person.name.type
string
>>> db.person.name.unique
False
>>> db.person.name.notnull
False
>>> db.person.name.length
32
including its parent table, tablename, and parent connection:
>>> db.person.name._table == db.person
True
>>> db.person.name._tablename == 'person'
True
>>> db.person.name._db == db
True
A field also has methods. Some of them are used to build queries and we
will see them later. A special method of the field object is
validate and it calls the validators for the field.
>>> db.person.name.validate('John')
('John', None)
which returns a tuple (value, error). error is None if the
input passes validation.
More on uploads
Consider the following model:
db.define_table('myfile',
Field('image', 'upload', default='path/to/file'))
In the case of an “upload” field, the default value can optionally be set to a path (an absolute path or a path relative to the current app folder), the default value is then assigned to each new record that does not specify an image.
Notice that this way multiple records may end to reference the same
default image file and this could be a problem on a Field having
autodelete enabled. When you do not want to allow duplicates for the
image field (i.e. multiple records referencing the same file) but still
want to set a default value for the “upload” then you need a way to copy
the default file for each new record that does not specify an image.
This can be obtained using a file-like object referencing the default
file as the default argument to Field, or even with:
Field('image', 'upload', default=dict(data='<file_content>', filename='<file_name>'))
Normally an insert is handled automatically via a Form but
occasionally you already have the file on the filesystem and want to
upload it programmatically. This can be done in this way:
with open(filename, 'rb') as stream:
db.myfile.insert(image=db.myfile.image.store(stream, filename))
It is also possible to insert a file in a simpler way and have the
insert method call store automatically:
with open(filename, 'rb') as stream:
db.myfile.insert(image=stream)
In this case the filename is obtained from the stream object if available.
The store method of the upload field object takes a file stream and
a filename. It uses the filename to determine the extension (type) of
the file, creates a new temp name for the file (according to py4web
upload mechanism) and loads the file content in this new temp file
(under the uploads folder unless specified otherwise). It returns the
new temp name, which is then stored in the image field of the
db.myfile table.
Note, if the file is to be stored in an associated blob field rather
than the file system, the store method will not insert the file in
the blob field (because store is called before the insert), so the
file must be explicitly inserted into the blob field:
db.define_table('myfile',
Field('image', 'upload', uploadfield='image_file'),
Field('image_file', 'blob'))
with open(filename, 'rb') as stream:
db.myfile.insert(image=db.myfile.image.store(stream, filename),
image_file=stream.read())
The retrieve method does the opposite of store.
When uploaded files are stored on filesystem (as in the case of a plain
Field('image', 'upload')) the code:
row = db(db.myfile).select().first()
(filename, fullname) = db.myfile.image.retrieve(row.image, nameonly=True)
retrieves the original file name (filename) as seen by the user at upload time and the name of stored file (fullname, with path relative to application folder). While in general the call:
(filename, stream) = db.myfile.image.retrieve(row.image)
retrieves the original file name (filename) and a file-like object ready to access uploaded file data (stream).
Notice that the stream returned by
retrieveis a real file object in the case that uploaded files are stored on filesystem. In that case remember to close the file when you are done, callingstream.close().
Here is an example of safe usage of retrieve:
from contextlib import closing
import shutil
row = db(db.myfile).select().first()
(filename, stream) = db.myfile.image.retrieve(row.image)
with closing(stream) as src, closing(open(filename, 'wb')) as dest:
shutil.copyfileobj(src, dest)
Migrations
With our example table definition:
db.define_table('person')
define_table checks whether or not the corresponding table exists.
If it does not, it generates the SQL to create it and executes the SQL.
If the table does exist but differs from the one being defined, it
generates the SQL to alter the table and executes it. If a field has
changed type but not name, it will try to convert the data (If you do
not want this, you need to redefine the table twice, the first time,
letting py4web drop the field by removing it, and the second time adding
the newly defined field so that py4web can create it). If the table
exists and matches the current definition, it will leave it alone. In
all cases it will create the db.person object that represents the
table.
We refer to this behavior as a “migration”. py4web logs all migrations and migration attempts in the file “sql.log”.
Note
by default py4web uses the “app/databases” folder for the
log file and all other migration files it needs. You can change this
setting by changing the folder argument to DAL. To set a different
log file name, for example “migrate.log” you can do
db = DAL(..., adapter_args=dict(logfile='migrate.log'))
The first argument of define_table is always the table name. The
other unnamed arguments are the fields. The function also takes
an optional keyword argument called “migrate”:
db.define_table('person', ..., migrate='person.table')
The value of migrate is the filename where py4web stores internal
migration information for this table. These files are very important and
should never be removed while the corresponding tables exist. In cases
where a table has been dropped and the corresponding file still exist,
it can be removed manually. By default, migrate is set to True. This
causes py4web to generate the filename from a hash of the connection
string. If migrate is set to False, the migration is not performed, and
py4web assumes that the table exists in the datastore and it contains
(at least) the fields listed in define_table.
There may not be two tables in the same application with the same migrate filename.
The DAL class also takes a “migrate” argument, which determines the
default value of migrate for calls to define_table. For example,
db = DAL('sqlite://storage.sqlite', migrate=False)
will set the default value of migrate to False whenever
db.define_table is called without a migrate argument.
Note
py4web only migrates new columns, removed columns, and
changes in column type (except in SQLite). py4web does not migrate
changes in attributes such as changes in the values of default,
unique, notnull, and ondelete.
Migrations can be disabled for all tables at once:
db = DAL(..., migrate_enabled=False)
This is the recommended behavior when two apps share the same database. Only one of the two apps should perform migrations, the other should disable them.
Fixing broken migrations
There are two common problems with migrations and there are ways to recover from them.
One problem is specific with SQLite. SQLite does not enforce column types and cannot drop columns. This means that if you have a column of type string and you remove it, it is not really removed. If you add the column again with a different type (for example datetime) you end up with a datetime column that contains strings (junk for practical purposes). py4web does not complain about this because it does not know what is in the database, until it tries to retrieve records and fails.
If py4web returns an error in some parse function when selecting records, most likely this is due to corrupted data in a column because of the above issue.
The solution consists in updating all records of the table and updating the values in the column in question with None.
The other problem is more generic but typical with MySQL. MySQL does not allow more than one ALTER TABLE in a transaction. This means that py4web must break complex transactions into smaller ones (one ALTER TABLE at the time) and commit one piece at the time. It is therefore possible that part of a complex transaction gets committed and one part fails, leaving py4web in a corrupted state. Why would part of a transaction fail? Because, for example, it involves altering a table and converting a string column into a datetime column, py4web tries to convert the data, but the data cannot be converted. What happens to py4web? It gets confused about what exactly is the table structure actually stored in the database.
The solution consists of enabling fake migrations:
db.define_table(...., migrate=True, fake_migrate=True)
This will rebuild py4web metadata about the table according to the table
definition. Try multiple table definitions to see which one works (the
one before the failed migration and the one after the failed migration).
Once successful remove the fake_migrate=True parameter.
Before attempting to fix migration problems it is prudent to make a copy of “yourapp/databases/*.table” files.
Migration problems can also be fixed for all tables at once:
db = DAL(..., fake_migrate_all=True)
This also fails if the model describes tables that do not exist in the database, but it can help narrowing down the problem.
Migration control summary
The logic of the various migration arguments are summarized in this pseudo-code:
if DAL.migrate_enabled and table.migrate:
if DAL.fake_migrate_all or table.fake_migrate:
perform fake migration
else:
perform migration
Table methods
insert
Given a table, you can insert records
>>> db.person.insert(name="Alex")
1
>>> db.person.insert(name="Bob")
2
Insert returns the unique “id” value of each record inserted.
You can truncate the table, i.e., delete all records and reset the counter of the id.
>>> db.person.truncate()
Now, if you insert a record again, the counter starts again at 1 (this is back-end specific and does not apply to Google NoSQL):
>>> db.person.insert(name="Alex")
1
Notice you can pass a parameter to truncate, for example you can
tell SQLite to restart the id counter.
>>> db.person.truncate('RESTART IDENTITY CASCADE')
The argument is in raw SQL and therefore engine specific.
py4web also provides a bulk_insert method
>>> db.person.bulk_insert([{'name': 'Alex'}, {'name': 'John'}, {'name': 'Tim'}])
[3, 4, 5]
It takes a list of dictionaries of fields to be inserted and performs multiple inserts at once. It returns the list of “id” values of the inserted records. On the supported relational databases there is no advantage in using this function as opposed to looping and performing individual inserts but on Google App Engine NoSQL, there is a major speed advantage.
Query, Set, Rows
Let’s consider again the table defined (and dropped) previously and insert three records:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> db.person.insert(name="Alex")
1
>>> db.person.insert(name="Bob")
2
>>> db.person.insert(name="Carl")
3
You can store the table in a variable. For example, with variable
person, you could do:
>>> person = db.person
You can also store a field in a variable such as name. For example,
you could also do:
>>> name = person.name
You can even build a query (using operators like ==, !=, <, >, <=, >=,
like, belongs) and store the query in a variable q such as in:
>>> q = name == 'Alex'
When you call db with a query, you define a set of records. You can
store it in a variable s and write:
>>> s = db(q)
Notice that no database query has been performed so far. DAL + Query simply define a set of records in this db that match the query. py4web determines from the query which table (or tables) are involved and, in fact, there is no need to specify that.
update_or_insert
Some times you need to perform an insert only if there is no record with the same values as those being inserted. This can be done with
db.define_table('person',
Field('name'),
Field('birthplace'))
db.person.update_or_insert(name='John', birthplace='Chicago')
The record will be inserted only if there is no other user called John born in Chicago.
You can specify which values to use as a key to determine if the record exists. For example:
db.person.update_or_insert(db.person.name == 'John',
name='John',
birthplace='Chicago')
and if there is John his birthplace will be updated else a new record will be created.
The selection criteria in the example above is a single field. It can also be a query, such as
db.person.update_or_insert((db.person.name == 'John') & (db.person.birthplace == 'Chicago'),
name='John',
birthplace='Chicago',
pet='Rover')
validate_and_insert, validate_and_update
The function
ret = db.mytable.validate_and_insert(field='value')
works very much like
id = db.mytable.insert(field='value')
except that it calls the validators for the fields before performing the
insert and bails out if the validation does not pass. If validation does
not pass the errors can be found in ret["errors"]. ret["errors"] holds
a key-value mapping where each key is the field name whose validation
failed, and the value of the key is the result from the validation error
(much like form["errors"]). If it passes, the id of the new record is
in ret["id"]. Mind that normally validation is done by the form
processing logic so this function is rarely needed.
Similarly
ret = db(query).validate_and_update(field='value')
works very much the same as
num = db(query).update(field='value')
except that it calls the validators for the fields before performing the
update. Notice that it only works if query involves a single table. The
number of updated records can be found in ret["updated"] and errors
will be in ret["errors"].
drop
Finally, you can drop tables and all data will be lost:
db.person.drop()
QueryBuilder
You can generate DAL queries using natural language. This can be done as follows:
from py4web import DAL, Field
from pydal import QueryBuilder, QueryParseError
db = DAL("sqlite:memory")
db.define_table("thing", Field("name"), Field("solid", "boolean"))
builder = QueryBuilder(db.thing)
query = builder.parse('name is equal to Chair')
rows = db(query).select()
Example of valid expressions are:
name is null
name is not null
name == Chair
name is Chair
name is equal Chair
name is equal to Chair
name is equal to “Chair”
name lower is equal to Chair
not name lower is equal to Chair
not (name lower is equal to Chair)
name == Chair or name == Table
name starts with C and name contains air
name in Chair, Table, Glass
name belongs Chair, Table, “Glass Top”
solid is true
solid is false
Notice that quotes are optional and only for values. You can use brakets to group. It throws a QueryParseError exception on failure. You can pass optional parameters to QueryBuilder for internationalization purposes (Italian in example):
builder = QueryBuilder(db.thing,
field_aliases={"id": "id", "nome": "name"},
token_aliases={"non è nullo": "is not null", "è uguale a": "=="})
query = builder.parse('nome non è nullo')
query = builder.parse('nome è uguale a Tavolo')
If field_aliases is not provided, only readable fields can be searched. If field_aliases is provided, only explicitedly included field names can be searched.
You can, of course, use the translation operator T:
builder = QueryBuilder(db.thing,
field_aliases={str(T(field.name)): field name for field in db.thing},
token_aliases={str(T(key):key) for key in QueryBuilder.token_ops})
You can alias the following tokens:
{
# boolean tokens
"not",
"and",
"or",
# field transformers
"upper",
"lower",
# unary search expressions
"is null",
"is not null",
"is true",
"is false",
# binary search expressions
"==",
"!=",
"<",
">",
"<=",
">=",
"contains",
"startswith", # notice "starts with" is an alias!
# search in list
"belongs",
}
The query builder is used in the Grid. In the Grid the field aliases are the field.label in lower case with the spaces replaced by underscore.
Tagging records
Tags allows to add or find properties attached to records in your database.
from py4web import DAL, Field
from pydal.tools.tags import Tags
db = DAL("sqlite:memory")
db.define_table("thing", Field("name"))
id1 = db.thing.insert(name="chair")
id2 = db.thing.insert(name="table")
properties = Tags(db.thing)
properties.add(id1, "color/red")
properties.add(id1, "style/modern")
properties.add(id2, "color/green")
properties.add(id2, "material/wood")
assert properties.get(id1) == ["color/red", "style/modern"]
assert properties.get(id2) == ["color/green", "material/wood"]
rows = db(properties.find(["style/modern"])).select()
assert rows.first().id == id1
rows = db(properties.find(["material/wood"])).select()
assert rows.first().id == id2
rows = db(properties.find(["color"])).select()
assert len(rows) == 2
Tags are hierarchical. Then find([“color”]) would return id1 and id2
because both records have tags with “color”.
It is internally implemented with the creation of an additional table, which in
this example would be db.thing_tags_default, because no tail was
specified on the Tags(table, tail=“default”) constructor.
py4web uses Tags as a flexible mechanism to manage permissions, we’ll see
all the details later on the Authorization using Tags chapter.
Raw SQL
executesql
The DAL allows you to explicitly issue SQL statements.
>>> db.executesql('SELECT * FROM person;')
[(1, u'Massimo'), (2, u'Massimo')]
In this case, the return values are not parsed or transformed by the DAL, and the format depends on the specific database driver. This usage with selects is normally not needed, but it is more common with indexes.
executesql takes five optional arguments: placeholders,
as_dict, fields, colnames, and as_ordered_dict.
placeholders is an optional sequence of values to be substituted in
or, if supported by the DB driver, a dictionary with keys matching named
placeholders in your SQL.
If as_dict is set to True, the results cursor returned by the DB
driver will be converted to a sequence of dictionaries keyed with the db
field names. Results returned with as_dict = True are the same as
those returned when applying as_list() to a normal select:
[{'field1': val1_row1, 'field2': val2_row1}, {'field1': val1_row2, 'field2': val2_row2}]
as_ordered_dict is pretty much like as_dict but the former
ensures that the order of resulting fields (OrderedDict keys) reflect
the order on which they are returned from DB driver:
[OrderedDict([('field1', val1_row1), ('field2', val2_row1)]),
OrderedDict([('field1', val1_row2), ('field2', val2_row2)])]
The fields argument is a list of DAL Field objects that match the
fields returned from the DB. The Field objects should be part of one or
more Table objects defined on the DAL object. The fields list can
include one or more DAL Table objects in addition to or instead of
including Field objects, or it can be just a single table (not in a
list). In that case, the Field objects will be extracted from the
table(s).
Instead of specifying the fields argument, the colnames argument
can be specified as a list of field names in tablename.fieldname format.
Again, these should represent tables and fields defined on the DAL
object.
It is also possible to specify both fields and the associated
colnames. In that case, fields can also include DAL Expression
objects in addition to Field objects. For Field objects in “fields”, the
associated colnames must still be in tablename.fieldname format. For
Expression objects in fields, the associated colnames can be any
arbitrary labels.
Notice, the DAL Table objects referred to by fields or colnames
can be dummy tables and do not have to represent any real tables in the
database. Also, note that the fields and colnames must be in the
same order as the fields in the results cursor returned from the DB.
_lastsql
Whether SQL was executed manually using executesql or was SQL generated
by the DAL, you can always find the SQL code in db._lastsql. This is
useful for debugging purposes:
>>> rows = db().select(db.person.ALL)
>>> db._lastsql
SELECT person.id, person.name FROM person;
py4web never generates queries using the “*” operator. py4web is always explicit when selecting fields.
Timing queries
All queries are automatically timed by py4web. The variable
db._timings is a list of tuples. Each tuple contains the raw SQL
query as passed to the database driver and the time it took to execute
in seconds.
Indexes
Currently the DAL API does not provide a command to create indexes on
tables, but this can be done using the executesql command. This is
because the existence of indexes can make migrations complex, and it is
better to deal with them explicitly. Indexes may be needed for those
fields that are used in recurrent queries.
Here is an example of how to:
db = DAL('sqlite://storage.sqlite')
db.define_table('person', Field('name'))
db.executesql('CREATE INDEX IF NOT EXISTS myidx ON person (name);')
Other database dialects have very similar syntaxes but may not support the optional “IF NOT EXISTS” directive.
Generating raw SQL
Sometimes you need to generate the SQL but not execute it. This is easy to do with py4web since every command that performs database IO has an equivalent command that does not, and simply returns the SQL that would have been executed. These commands have the same names and syntax as the functional ones, but they start with an underscore:
Here is _insert
>>> print(db.person._insert(name='Alex'))
INSERT INTO "person"("name") VALUES ('Alex');
Here is _count
>>> print(db(db.person.name == 'Alex')._count())
SELECT COUNT(*) FROM "person" WHERE ("person"."name" = 'Alex');
Here is _select
>>> print(db(db.person.name == 'Alex')._select())
SELECT "person"."id", "person"."name" FROM "person" WHERE ("person"."name" = 'Alex');
Here is _delete
>>> print(db(db.person.name == 'Alex')._delete())
DELETE FROM "person" WHERE ("person"."name" = 'Alex');
And finally, here is _update
>>> print(db(db.person.name == 'Alex')._update(name='Susan'))
UPDATE "person" SET "name"='Susan' WHERE ("person"."name" = 'Alex');
Moreover you can always use
db._lastsqlto return the most recent SQL code, whether it was executed manually using executesql or was SQL generated by the DAL.
select command
Given a Set, s, you can fetch the records with the command
select:
>>> rows = s.select()
It returns an iterable object of class pydal.objects.Rows whose
elements are Row objects. pydal.objects.Row objects act like
dictionaries, but their elements can also be accessed as attributes.
The former differ from the latter because
its values are read-only.
The Rows object allows looping over the result of the select and printing the selected field values for each row:
>>> for row in rows:
... print(row.id, row.name)
...
1 Alex
You can do all the steps in one statement:
>>> for row in db(db.person.name == 'Alex').select():
... print(row.name)
...
Alex
The select command can take arguments. All unnamed arguments are interpreted as the names of the fields that you want to fetch. For example, you can be explicit on fetching field “id” and field “name”:
>>> for row in db().select(db.person.id, db.person.name):
... print(row.name)
...
Alex
Bob
Carl
The table attribute ALL allows you to specify all fields:
>>> for row in db().select(db.person.ALL):
... print(row.id, row.name)
...
1 Alex
2 Bob
3 Carl
Notice that there is no query string passed to db. py4web understands that if you want all fields of the table person without additional information then you want all records of the table person.
An equivalent alternative syntax is the following:
>>> for row in db(db.person).select():
... print(row.id, row.name)
...
1 Alex
2 Bob
3 Carl
and py4web understands that if you ask for all records of the table person without additional information, then you want all the fields of table person.
Given one row
>>> row = rows[0]
you can extract its values using multiple equivalent expressions:
>>> row.name
Alex
>>> row['name']
Alex
>>> row('person.name')
Alex
The latter syntax is particularly handy when selecting an expression instead of a column. We will show this later.
You can also do
rows.compact = False
to disable the notation
rows[i].name
and enable, instead, the less compact notation:
rows[i].person.name
Yes this is unusual and rarely needed.
Row objects also have two important methods:
row.delete_record()
and
row.update_record(name="new value")
Using an iterator-based select for lower memory use
Python “iterators” are a type of “lazy-evaluation”. They ‘feed’ data one step at time; traditional Python loops create the entire set of data in memory before looping.
The traditional use of select is:
for row in db(db.table).select():
...
but for large numbers of rows, using an iterator-based alternative has dramatically lower memory use:
for row in db(db.table).iterselect():
...
Testing shows this is around 10% faster as well, even on machines with large RAM.
Rendering rows using represent
You may wish to rewrite rows returned by select to take advantage of formatting information contained in the represents setting of the fields.
rows = db(query).select()
repr_row = rows.render(0)
If you don’t specify an index, you get a generator to iterate over all the rows:
for row in rows.render():
print(row.myfield)
Can also be applied to slices:
for row in rows[0:10].render():
print(row.myfield)
If you only want to transform selected fields via their “represent” attribute, you can list them in the “fields” argument:
repr_row = row.render(0, fields=[db.mytable.myfield])
Note, it returns a transformed copy of the original Row, so there’s no update_record (which you wouldn’t want anyway) or delete_record.
Shortcuts
The DAL supports various code-simplifying shortcuts. In particular:
myrecord = db.mytable[id]
returns the record with the given id if it exists. If the id
does not exist, it returns None. The above statement is equivalent
to
myrecord = db(db.mytable.id == id).select().first()
You can delete records by id:
del db.mytable[id]
and this is equivalent to
db(db.mytable.id == id).delete()
and deletes the record with the given id, if it exists.
Note: this delete shortcut syntax does not currently work if versioning is activated
You can insert records:
db.mytable[None] = dict(myfield='somevalue')
It is equivalent to
db.mytable.insert(myfield='somevalue')
and it creates a new record with field values specified by the dictionary on the right hand side.
Note: insert shortcut was previously db.table[0] = .... It has
changed in pyDAL 19.02 to permit normal usage of id 0.
You can update records:
db.mytable[id] = dict(myfield='somevalue')
which is equivalent to
db(db.mytable.id == id).update(myfield='somevalue')
and it updates an existing record with field values specified by the dictionary on the right hand side.
Fetching a Row
Yet another convenient syntax is the following:
record = db.mytable(id)
record = db.mytable(db.mytable.id == id)
record = db.mytable(id, myfield='somevalue')
Apparently similar to db.mytable[id] the above syntax is more
flexible and safer. First of all it checks whether id is an int (or
str(id) is an int) and returns None if not (it never raises an
exception). It also allows to specify multiple conditions that the
record must meet. If they are not met, it also returns None.
Recursive selects
Consider the previous table person and a new table “thing” referencing a “person”:
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
and a simple select from this table:
things = db(db.thing).select()
which is equivalent to
things = db(db.thing._id != None).select()
where _id is a reference to the primary key of the table. Normally
db.thing._id is the same as db.thing.id and we will assume that
in most of this book.
For each Row of things it is possible to fetch not just fields from the selected table (thing) but also from linked tables (recursively):
for thing in things:
print(thing.name, thing.owner_id.name)
Here thing.owner_id.name requires one database select for each thing
in things and it is therefore inefficient. We suggest using joins
whenever possible instead of recursive selects, nevertheless this is
convenient and practical when accessing individual records.
You can also do it backwards, by selecting the things referenced by a person:
person = db.person(id)
for thing in person.thing.select(orderby=db.thing.name):
print(person.name, 'owns', thing.name)
In this last expression person.thing is a shortcut for
db(db.thing.owner_id == person.id)
i.e. the Set of things referenced by the current person. This
syntax breaks down if the referencing table has multiple references to
the referenced table. In this case one needs to be more explicit and use
a full Query.
orderby, groupby, limitby, distinct, having, orderby_on_limitby, join, left, cache
The select command takes a number of optional arguments.
orderby
You can fetch the records sorted by name:
>>> for row in db().select(db.person.ALL, orderby=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
You can fetch the records sorted by name in reverse order (notice the tilde):
>>> for row in db().select(db.person.ALL, orderby=~db.person.name):
... print(row.name)
...
Carl
Bob
Alex
You can have the fetched records appear in random order:
>>> for row in db().select(db.person.ALL, orderby='<random>'):
... print(row.name)
...
Carl
Alex
Bob
The use of
orderby='<random>'is not supported on Google NoSQL. However, to overcome this limit, sorting can be accomplished on selected rows:
import random
rows = db(...).select().sort(lambda row: random.random())
You can sort the records according to multiple fields by concatenating them with a “|”:
>>> for row in db().select(db.person.name, orderby=db.person.name|db.person.id):
... print(row.name)
...
Alex
Bob
Carl
groupby, having
Using groupby together with orderby, you can group records with
the same value for the specified field (this is back-end specific, and
is not on the Google NoSQL):
>>> for row in db().select(db.person.ALL,
... orderby=db.person.name,
... groupby=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
You can use having in conjunction with groupby to group
conditionally (only those having the condition are grouped).
db(query1).select(db.person.ALL, groupby=db.person.name, having=query2)
Notice that query1 filters records to be displayed, query2 filters records to be grouped.
distinct
With the argument distinct=True, you can specify that you only want
to select distinct records. This has the same effect as grouping using
all specified fields except that it does not require sorting. When using
distinct it is important not to select ALL fields, and in particular not
to select the “id” field, else all records will always be distinct.
Here is an example:
>>> for row in db().select(db.person.name, distinct=True):
... print(row.name)
...
Alex
Bob
Carl
Notice that distinct can also be an expression, for example:
>>> for row in db().select(db.person.name, distinct=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
limitby
With limitby=(min, max), you can select a subset of the records from
offset=min to but not including offset=max. In the next example we
select the first two records starting at zero:
>>> for row in db().select(db.person.ALL, limitby=(0, 2)):
... print(row.name)
...
Alex
Bob
orderby_on_limitby
Note that the DAL defaults to implicitly adding an orderby when using a
limitby. This ensures the same query returns the same results each time,
important for pagination. But it can cause performance problems. use
orderby_on_limitby = False to change this (this defaults to True).
join, left
These are involved in managing One to many relation. They are described in Inner join and Left outer join sections respectively.
cache, cacheable
An example use which gives much faster selects is:
rows = db(query).select(cache=(cache.get, 3600), cacheable=True)
Look at Caching selects, to understand what the trade-offs are.
Logical operators
Queries can be combined using the binary AND operator “&”:
>>> rows = db((db.person.name=='Alex') & (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
>>> len(rows)
0
and the binary OR operator “|”:
>>> rows = db((db.person.name == 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
1 Alex
You can negate a sub-query inverting its operator:
>>> rows = db((db.person.name != 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
2 Bob
3 Carl
or by explicit negation with the “~” unary operator:
>>> rows = db(~(db.person.name == 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
2 Bob
3 Carl
Due to Python restrictions in overloading “
and” and “or” operators, these cannot be used in forming queries. The binary operators “&” and “|” must be used instead. Note that these operators (unlike “and” and “or”) have higher precedence than comparison operators, so the “extra” parentheses in the above examples are mandatory. Similarly, the unary operator “~” has higher precedence than comparison operators, so~-negated comparisons must also be parenthesized.
It is also possible to build queries using in-place logical operators:
>>> query = db.person.name != 'Alex'
>>> query &= db.person.id > 3
>>> query |= db.person.name == 'John'
count, isempty, delete, update
You can count records in a set:
>>> db(db.person.name != 'William').count()
3
Notice that count takes an optional distinct argument which
defaults to False, and it works very much like the same argument for
select. count has also a cache argument that works very much
like the equivalent argument of the select method.
Sometimes you may need to check if a table is empty. A more efficient
way than counting is using the isempty method:
>>> db(db.person).isempty()
False
You can delete records in a set:
>>> db(db.person.id > 3).delete()
0
The delete method returns the number of records that were deleted.
And you can update all records in a set by passing named arguments corresponding to the fields that need to be updated:
>>> db(db.person.id > 2).update(name='Ken')
1
The update method returns the number of records that were updated.
Expressions
The value assigned an update statement can be an expression. For example consider this model
db.define_table('person',
Field('name'),
Field('visits', 'integer', default=0))
db(db.person.name == 'Massimo').update(visits = db.person.visits + 1)
The values used in queries can also be expressions
db.define_table('person',
Field('name'),
Field('visits', 'integer', default=0),
Field('clicks', 'integer', default=0))
db(db.person.visits == db.person.clicks + 1).delete()
case
An expression can contain a case clause for example:
>>> condition = db.person.name.startswith('B')
>>> yes_or_no = condition.case('Yes', 'No')
>>> for row in db().select(db.person.name, yes_or_no):
... print(row.person.name, row[yes_or_no]) # could be row(yes_or_no) too
...
Alex No
Bob Yes
Ken No
update_record
py4web also allows updating a single record that is already in memory
using update_record
>>> row = db(db.person.id == 2).select().first()
>>> row.update_record(name='Curt')
<Row {'id': 2, 'name': 'Curt'}>
update_record should not be confused with
>>> row.update(name='Curt')
because for a single row, the method update updates the row object
but not the database record, as in the case of update_record.
It is also possible to change the attributes of a row (one at a time)
and then call update_record() without arguments to save the changes:
>>> row = db(db.person.id > 2).select().first()
>>> row.name = 'Philip'
>>> row.update_record() # saves above change
<Row {'id': 3, 'name': 'Philip'}>
Note, you should avoid using
row.update_record()with no arguments when therowobject contains fields that have anupdateattribute (e.g.,Field('modified_on', update=datetime.datetime.utcnow)). Callingrow.update_record()will retain all of the existing values in therowobject, so any fields withupdateattributes will have no effect in this case. Be particularly mindful of this with tables that includeauth.signature.
The update_record method is available only if the table’s id
field is included in the select, and cacheable is not set to
True.
Inserting and updating from a dictionary
A common issue consists of needing to insert or update records in a
table where the name of the table, the field to be updated, and the
value for the field are all stored in variables. For example:
tablename, fieldname, and value.
The insert can be done using the following syntax:
db[tablename].insert(**{fieldname:value})
The update of record with given id can be done with:
db(db[tablename]._id == id).update(**{fieldname:value})
Notice we used table._id instead of table.id. In this way the
query works even for tables with a primary key field with type other
than “id”.
first and last
Given a Rows object containing records:
rows = db(query).select()
first_row = rows.first()
last_row = rows.last()
are equivalent to
first_row = rows[0] if len(rows) else None
last_row = rows[-1] if len(rows) else None
Notice, first() and last() allow you to obtain obviously the
first and last record present in your query, but this won’t mean that
these records are going to be the first or last inserted records. In
case you want the first or last record inputted in a given table don’t
forget to use orderby=db.table_name.id. If you forget you will only
get the first and last record returned by your query which are often in
a random order determined by the backend query optimiser.
as_dict and as_list
A Row object can be serialized into a regular dictionary using the
as_dict() method and a Rows object can be serialized into a list of
dictionaries using the as_list() method. Here are some examples:
rows = db(query).select()
rows_list = rows.as_list()
first_row_dict = rows.first().as_dict()
These methods are convenient for passing Rows to generic views and or to store Rows in sessions (Rows objects themselves cannot be serialized because they contain a reference to an open DB connection):
rows = db(query).select()
session.rows = rows # not allowed!
session.rows = rows.as_list() # allowed!
Combining rows
Rows objects can be combined at the Python level. Here we assume:
>>> print(rows1)
person.name
Max
Tim
>>> print(rows2)
person.name
John
Tim
You can do union of the records in two sets of rows:
>>> rows3 = rows1 + rows2
>>> print(rows3)
person.name
Max
Tim
John
Tim
You can do union of the records removing duplicates:
>>> rows3 = rows1 | rows2
>>> print(rows3)
person.name
Max
Tim
John
You can do intersection of the records in two sets of rows:
>>> rows3 = rows1 & rows2
>>> print(rows3)
person.name
Tim
find, exclude, sort
Some times you need to perform two selects and one contains a subset of
a previous select. In this case it is pointless to access the database
again. The find, exclude and sort objects allow you to
manipulate a Rows object and generate another one without accessing the
database. More specifically: - find returns a new set of Rows
filtered by a condition and leaves the original unchanged. - exclude
returns a new set of Rows filtered by a condition and removes them from
the original Rows. - sort returns a new set of Rows sorted by a
condition and leaves the original unchanged.
All these methods take a single argument, a function that acts on each individual row.
Here is an example of usage:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> db.person.insert(name='John')
1
>>> db.person.insert(name='Max')
2
>>> db.person.insert(name='Alex')
3
>>> rows = db(db.person).select()
>>> for row in rows.find(lambda row: row.name[0]=='M'):
... print(row.name)
...
Max
>>> len(rows)
3
>>> for row in rows.exclude(lambda row: row.name[0]=='M'):
... print(row.name)
...
Max
>>> len(rows)
2
>>> for row in rows.sort(lambda row: row.name):
... print(row.name)
...
Alex
John
They can be combined:
>>> rows = db(db.person).select()
>>> rows = rows.find(lambda row: 'x' in row.name).sort(lambda row: row.name)
>>> for row in rows:
... print(row.name)
...
Alex
Max
Sort takes an optional argument reverse=True with the obvious
meaning.
The find method has an optional limitby argument with the same
syntax and functionality as the Set select method.
Caching selects
The select method also takes a cache argument, which defaults to
None. For caching purposes, it should be set to a tuple where the first
element is the cache function with signature (key, callback, expiration)
(for example cache.get assuming cache
is an instance of the py4web cache object), and
the second element is the expiration time in seconds.
In the following example, you see a controller that caches a select on the previously defined db.log table. The actual select fetches data from the back-end database no more frequently than once every 60 seconds and stores the result in memory. If the next call to this controller occurs in less than 60 seconds since the last database IO, it simply fetches the previous data from memory.
def cache_db_select():
logs = db().select(db.log.ALL, cache=(cache.get, 60))
return dict(logs=logs)
The select method has an optional cacheable argument, normally
set to False. When cacheable=True the resulting Rows is
serializable but The Rows lack update_record and
delete_record methods.
If you do not need these methods you can speed up selects a lot by
setting the cacheable attribute:
rows = db(query).select(cacheable=True)
When the cache argument is set but cacheable=False (default)
only the database results are cached, not the actual Rows object. When
the cache argument is used in conjunction with cacheable=True
the entire Rows object is cached and this results in much faster
caching:
rows = db(query).select(cache=(cache.get, 3600), cacheable=True)
Computed and Virtual fields
Computed fields
DAL fields may have a compute attribute. This must be a function (or
lambda) that takes a Row object and returns a value for the field. When
a new record is modified, including both insertions and updates, if a
value for the field is not provided, py4web tries to compute from the
other field values using the compute function. Here is an example:
>>> db.define_table('item',
... Field('unit_price', 'double'),
... Field('quantity', 'integer'),
... Field('total_price',
... compute=lambda r: r['unit_price'] * r['quantity']))
<Table item (id, unit_price, quantity, total_price)>
>>> rid = db.item.insert(unit_price=1.99, quantity=5)
>>> db.item[rid]
<Row {'total_price': '9.95', 'unit_price': 1.99, 'id': 1L, 'quantity': 5}>
Notice that the computed value is stored in the db and it is not computed on retrieval, as in the case of virtual fields, described next. Two typical applications of computed fields are:
in wiki applications, to store the processed input wiki text as HTML, to avoid re-processing on every request
for searching, to compute normalized values for a field, to be used for searching.
Computed fields are evaluated in the order in which they are defined in the table definition. A computed field can refer to previously defined computed fields.
Virtual fields
Virtual fields are also computed fields (as in the previous subsection) but they differ from those because they are virtual in the sense that they are not stored in the db and they are computed each time records are extracted from the database. They can be used to simplify the user’s code without using additional storage but they cannot be used for searching.
New style virtual fields (experimental)
py4web provides a new and easier way to define virtual fields and lazy virtual fields. This section is marked experimental because the APIs may still change a little from what is described here.
Here we will consider the same example as in the previous subsection. In particular we consider the following model:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
One can define a total_price virtual field as
db.item.total_price = Field.Virtual(lambda row: row.item.unit_price * row.item.quantity)
i.e. by simply defining a new field total_price to be a
Field.Virtual. The only argument of the constructor is a function
that takes a row and returns the computed values.
A virtual field defined as the one above is automatically computed for all records when the records are selected:
for row in db(db.item).select():
print(row.total_price)
It is also possible to define method fields which are calculated on-demand, when called. For example:
db.item.discounted_total = \
Field.Method(lambda row, discount=0.0:
row.item.unit_price * row.item.quantity * (100.0 - discount / 100))
In this case row.discounted_total is not a value but a function. The
function takes the same arguments as the function passed to the
Method constructor except for row which is implicit (think of it
as self for objects).
The lazy field in the example above allows one to compute the total
price for each item:
for row in db(db.item).select(): print(row.discounted_total())
And it also allows to pass an optional discount percentage (say
15%):
for row in db(db.item).select(): print(row.discounted_total(15))
Virtual and Method fields can also be defined in place when a table is defined:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'),
Field.Virtual('total_price', lambda row: ...),
Field.Method('discounted_total', lambda row, discount=0.0: ...))
Mind that virtual fields do not have the same attributes as regular fields (length, default, required, etc). They do not appear in the list of
db.table.fields.
Old style virtual fields
In order to define one or more virtual fields, you can also define a container class, instantiate it and link it to a table or to a select. For example, consider the following table:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
One can define a total_price virtual field as
class MyVirtualFields:
def total_price(self):
return self.item.unit_price * self.item.quantity
db.item.virtualfields.append(MyVirtualFields())
Notice that each method of the class that takes a single argument (self)
is a new virtual field. self refers to each one row of the select.
Field values are referred by full path as in self.item.unit_price.
The table is linked to the virtual fields by appending an instance of
the class to the table’s virtualfields attribute.
Virtual fields can also access recursive fields as in
db.define_table('item',
Field('unit_price', 'double'))
db.define_table('order_item',
Field('item', 'reference item'),
Field('quantity', 'integer'))
class MyVirtualFields:
def total_price(self):
return self.order_item.item.unit_price * self.order_item.quantity
db.order_item.virtualfields.append(MyVirtualFields())
Notice the recursive field access self.order_item.item.unit_price
where self is the looping record.
They can also act on the result of a JOIN
rows = db(db.order_item.item == db.item.id).select()
class MyVirtualFields:
def total_price(self):
return self.item.unit_price * self.order_item.quantity
rows.setvirtualfields(order_item=MyVirtualFields())
for row in rows:
print(row.order_item.total_price)
Notice how in this case the syntax is different. The virtual field
accesses both self.item.unit_price and self.order_item.quantity
which belong to the join select. The virtual field is attached to the
rows of the table using the setvirtualfields method of the rows
object. This method takes an arbitrary number of named arguments and can
be used to set multiple virtual fields, defined in multiple classes, and
attach them to multiple tables:
class MyVirtualFields1:
def discounted_unit_price(self):
return self.item.unit_price * 0.90
class MyVirtualFields2:
def total_price(self):
return self.item.unit_price * self.order_item.quantity
def discounted_total_price(self):
return self.item.discounted_unit_price * self.order_item.quantity
rows.setvirtualfields(item=MyVirtualFields1(),
order_item=MyVirtualFields2())
for row in rows:
print(row.order_item.discounted_total_price)
Virtual fields can be lazy; all they need to do is return a function and access it by calling the function:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
class MyVirtualFields:
def lazy_total_price(self):
def lazy(self=self):
return self.item.unit_price * self.item.quantity
return lazy
db.item.virtualfields.append(MyVirtualFields())
for item in db(db.item).select():
print(item.lazy_total_price())
or shorter using a lambda function:
class MyVirtualFields:
def lazy_total_price(self):
return lambda self=self: self.item.unit_price * self.item.quantity
Joins and Relations
One to many relation
To illustrate how to implement one to many relations with the DAL, define another table “thing” that refers to the table “person” which we redefine here:
>>> db.define_table('person',
... Field('name'))
<Table person (id, name)>
>>> db.person.insert(name='Alex')
1
>>> db.person.insert(name='Bob')
2
>>> db.person.insert(name='Carl')
3
>>> db.define_table('thing',
... Field('name'),
... Field('owner_id', 'reference person'))
<Table thing (id, name, owner_id)>
Table “thing” has two fields, the name of the thing and the owner of the
thing. The “owner_id” field is a reference field, it is intended that
the field reference the other table by its id. A reference type can be
specified in two equivalent ways, either:
Field('owner_id', 'reference person') or:
Field('owner_id', db.person).
The latter is always converted to the former. They are equivalent except in the case of lazy tables, self references or other types of cyclic references where the former notation is the only allowed notation.
Now, insert three things, two owned by Alex and one by Bob:
>>> db.thing.insert(name='Boat', owner_id=1)
1
>>> db.thing.insert(name='Chair', owner_id=1)
2
>>> db.thing.insert(name='Shoes', owner_id=2)
3
You can select as you did for any other table:
>>> for row in db(db.thing.owner_id == 1).select():
... print(row.name)
...
Boat
Chair
Because a thing has a reference to a person, a person can have many things, so a record of table person now acquires a new attribute thing, which is a Set, that defines the things of that person. This allows looping over all persons and fetching their things easily:
>>> for person in db().select(db.person.ALL):
... print(person.name)
... for thing in person.thing.select():
... print(' ', thing.name)
...
Alex
Boat
Chair
Bob
Shoes
Carl
Inner join
Another way to achieve a similar result is by using a join, specifically an INNER JOIN. py4web performs joins automatically and transparently when the query links two or more tables as in the following example:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Observe that py4web did a join, so the rows now contain two records, one from each table, linked together. Because the two records may have fields with conflicting names, you need to specify the table when extracting a field value from a row. This means that while before you could do:
row.name
and it was obvious whether this was the name of a person or a thing, in the result of a join you have to be more explicit and say:
row.person.name
or:
row.thing.name
There is an alternative syntax for INNER JOINS:
>>> rows = db(db.person).select(join=db.thing.on(db.person.id == db.thing.owner_id))
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
While the output is the same, the generated SQL in the two cases can be different. The latter syntax removes possible ambiguities when the same table is joined twice and aliased:
db.define_table('thing',
Field('name'),
Field('owner_id1', 'reference person'),
Field('owner_id2', 'reference person'))
rows = db(db.person).select(
join=[db.person.with_alias('owner_id1').on(db.person.id == db.thing.owner_id1),
db.person.with_alias('owner_id2').on(db.person.id == db.thing.owner_id2)])
The value of join can be list of db.table.on(...) to join.
Left outer join
Notice that Carl did not appear in the list above because he has no things. If you intend to select on persons (whether they have things or not) and their things (if they have any), then you need to perform a LEFT OUTER JOIN. This is done using the argument “left” of the select. Here is an example:
>>> rows = db().select(db.person.ALL, db.thing.ALL,
... left=db.thing.on(db.person.id == db.thing.owner_id))
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Carl has None
where:
left = db.thing.on(...)
does the left join query. Here the argument of db.thing.on is the
condition required for the join (the same used above for the inner
join). In the case of a left join, it is necessary to be explicit about
which fields to select.
Multiple left joins can be combined by passing a list or tuple of
db.mytable.on(...) to the left parameter.
Grouping and counting
When doing joins, sometimes you want to group rows according to certain criteria and count them. For example, count the number of things owned by every person. py4web allows this as well. First, you need a count operator. Second, you want to join the person table with the thing table by owner. Third, you want to select all rows (person + thing), group them by person, and count them while grouping:
>>> count = db.person.id.count()
>>> for row in db(db.person.id == db.thing.owner_id
... ).select(db.person.name, count, groupby=db.person.name):
... print(row.person.name, row[count])
...
Alex 2
Bob 1
Notice the count operator (which is built-in) is used as a field.
The only issue here is in how to retrieve the information. Each row
clearly contains a person and the count, but the count is not a field of
a person nor is it a table. So where does it go? It goes into the
storage object representing the record with a key equal to the query
expression itself.
The count method of the Field object has an optional distinct
argument. When set to True it specifies that only distinct values of
the field in question are to be counted.
Many to many relation
In the previous examples, we allowed a thing to have one owner but one person could have many things. What if Boat was owned by Alex and Curt? This requires a many-to-many relation, and it is realized via an intermediate table that links a person to a thing via an ownership relation.
Here is how to do it:
>>> db.define_table('person',
... Field('name'))
<Table person (id, name)>
>>> db.person.bulk_insert([dict(name='Alex'), dict(name='Bob'), dict(name='Carl')])
[1, 2, 3]
>>> db.define_table('thing',
... Field('name'))
<Table thing (id, name)>
>>> db.thing.bulk_insert([dict(name='Boat'), dict(name='Chair'), dict(name='Shoes')])
[1, 2, 3]
>>> db.define_table('ownership',
... Field('person', 'reference person'),
... Field('thing', 'reference thing'))
<Table ownership (id, person, thing)>
the existing ownership relationship can now be rewritten as:
>>> db.ownership.insert(person=1, thing=1) # Alex owns Boat
1
>>> db.ownership.insert(person=1, thing=2) # Alex owns Chair
2
>>> db.ownership.insert(person=2, thing=3) # Bob owns Shoes
3
Now you can add the new relation that Curt co-owns Boat:
>>> db.ownership.insert(person=3, thing=1) # Curt owns Boat too
4
Because you now have a three-way relation between tables, it may be convenient to define a new set on which to perform operations:
>>> persons_and_things = db((db.person.id == db.ownership.person) &
... (db.thing.id == db.ownership.thing))
Now it is easy to select all persons and their things from the new Set:
>>> for row in persons_and_things.select():
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Curt has Boat
Similarly, you can search for all things owned by Alex:
>>> for row in persons_and_things(db.person.name == 'Alex').select():
... print(row.thing.name)
...
Boat
Chair
and all owners of Boat:
>>> for row in persons_and_things(db.thing.name == 'Boat').select():
... print(row.person.name)
...
Alex
Curt
A lighter alternative to many-to-many relations is tagging, see the Authorization using Tags chapter. Tagging works even on database backends that do not support JOINs like the Google App Engine NoSQL.
Self-Reference and aliases
It is possible to define tables with fields that refer to themselves, here is an example:
db.define_table('person',
Field('name'),
Field('father_id', 'reference person'),
Field('mother_id', 'reference person'))
Notice that the alternative notation of using a table object as field type will fail in this case, because it uses a table before it is defined:
db.define_table('person',
Field('name'),
Field('father_id', db.person), # wrong!
Field('mother_id', db['person'])) # wrong!
In general db.tablename and 'reference tablename' are equivalent
field types, but the latter is the only one allowed for self-references.
When a table has a self-reference and you have to do join, for example to select a person and its father, you need an alias for the table. In SQL an alias is a temporary alternate name you can use to reference a table/column into a query (or other SQL statement).
With py4web you can make an alias for a table using the with_alias
method. This works also for expressions, which means also for fields
since Field is derived from Expression.
Here is an example:
>>> fid, mid = db.person.bulk_insert([dict(name='Massimo'), dict(name='Claudia')])
>>> db.person.insert(name='Marco', father_id=fid, mother_id=mid)
3
>>> Father = db.person.with_alias('father')
>>> Mother = db.person.with_alias('mother')
>>> type(Father)
<class 'pydal.objects.Table'>
>>> str(Father)
'person AS father'
>>> rows = db().select(db.person.name, Father.name, Mother.name,
... left=(Father.on(Father.id == db.person.father_id),
... Mother.on(Mother.id == db.person.mother_id)))
>>> for row in rows:
... print(row.person.name, row.father.name, row.mother.name)
...
Massimo None None
Claudia None None
Marco Massimo Claudia
Notice that we have chosen to make a distinction between: - “father_id”: the field name used in the table “person”; - “father”: the alias we want to use for the table referenced by the above field; this is communicated to the database; - “Father”: the variable used by py4web to refer to that alias.
The difference is subtle, and there is nothing wrong in using the same name for the three of them:
>>> db.define_table('person',
... Field('name'),
... Field('father', 'reference person'),
... Field('mother', 'reference person'))
<Table person (id, name, father, mother)>
>>> fid, mid = db.person.bulk_insert([dict(name='Massimo'), dict(name='Claudia')])
>>> db.person.insert(name='Marco', father=fid, mother=mid)
3
>>> father = db.person.with_alias('father')
>>> mother = db.person.with_alias('mother')
>>> rows = db().select(db.person.name, father.name, mother.name,
... left=(father.on(father.id==db.person.father),
... mother.on(mother.id==db.person.mother)))
>>> for row in rows:
... print(row.person.name, row.father.name, row.mother.name)
...
Massimo None None
Claudia None None
Marco Massimo Claudia
But it is important to have the distinction clear in order to build correct queries.
Other operators
py4web has other operators that provide an API to access equivalent SQL operators. Let’s define another table “log” to store security events, their event_time and severity, where the severity is an integer number.
>>> db.define_table('log', Field('event'),
... Field('event_time', 'datetime'),
... Field('severity', 'integer'))
<Table log (id, event, event_time, severity)>
As before, insert a few events, a “port scan”, an “xss injection” and an “unauthorized login”. For the sake of the example, you can log events with the same event_time but with different severities (1, 2, and 3 respectively).
>>> import datetime
>>> now = datetime.datetime.now()
>>> db.log.insert(event='port scan', event_time=now, severity=1)
1
>>> db.log.insert(event='xss injection', event_time=now, severity=2)
2
>>> db.log.insert(event='unauthorized login', event_time=now, severity=3)
3
like, ilike, regexp, startswith, endswith, contains, upper, lower
Fields have a like operator that you can use to match strings:
>>> for row in db(db.log.event.like('port%')).select():
... print(row.event)
...
port scan
Here “port%” indicates a string starting with “port”. The percent sign character, “%”, is a wild-card character that means “any sequence of characters”.
The like operator maps to the LIKE word in ANSI-SQL. LIKE is
case-sensitive in most databases, and depends on the collation of the
database itself. The like method is hence case-sensitive but it can
be made case-insensitive with
db.mytable.myfield.like('value', case_sensitive=False)
which is the same as using ilike
db.mytable.myfield.ilike('value')
py4web also provides some shortcuts:
db.mytable.myfield.startswith('value')
db.mytable.myfield.endswith('value')
db.mytable.myfield.contains('value')
which are roughly equivalent respectively to
db.mytable.myfield.like('value%')
db.mytable.myfield.like('%value')
db.mytable.myfield.like('%value%')
Remember that contains has a special meaning for list:<type>
fields, as discussed in list:<type> and contains.
The contains method can also be passed a list of values and an
optional boolean argument all to search for records that contain all
values:
db.mytable.myfield.contains(['value1', 'value2'], all=True)
or any value from the list
db.mytable.myfield.contains(['value1', 'value2'], all=False)
There is a also a regexp method that works like the like method
but allows regular expression syntax for the look-up expression. It is
only supported by MySQL, Oracle, PostgreSQL, SQLite, and MongoDB (with
different degree of support).
The upper and lower methods allow you to convert the value of
the field to upper or lower case, and you can also combine them with the
like operator:
>>> for row in db(db.log.event.upper().like('PORT%')).select():
... print(row.event)
...
port scan
year, month, day, hour, minutes, seconds
The date and datetime fields have day, month and year
methods. The datetime and time fields have hour, minutes and
seconds methods. Here is an example:
>>> for row in db(db.log.event_time.year() > 2018).select():
... print(row.event)
...
port scan
xss injection
unauthorized login
belongs
The SQL IN operator is realized via the belongs method which returns
true when the field value belongs to the specified set (list or tuples):
>>> for row in db(db.log.severity.belongs((1, 2))).select():
... print(row.event)
...
port scan
xss injection
The DAL also allows a nested select as the argument of the belongs
operator. The only caveat is that the nested select has to be a
_select, not a select, and only one field has to be selected
explicitly, the one that defines the set.
>>> bad_days = db(db.log.severity == 3)._select(db.log.event_time)
>>> for row in db(db.log.event_time.belongs(bad_days)).select():
... print(row.severity, row.event)
...
1 port scan
2 xss injection
3 unauthorized login
In those cases where a nested select is required and the look-up field is a reference we can also use a query as argument. For example:
db.define_table('person', Field('name'))
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
db(db.thing.owner_id.belongs(db.person.name == 'Jonathan')).select()
In this case it is obvious that the nested select only needs the field
referenced by the db.thing.owner_id field so we do not need the more
verbose _select notation.
A nested select can also be used as insert/update value but in this case the syntax is different:
lazy = db(db.person.name == 'Jonathan').nested_select(db.person.id)
db(db.thing.id == 1).update(owner_id = lazy)
In this case lazy is a nested expression that computes the id of
person “Jonathan”. The two lines result in one single SQL query.
sum, avg, min, max and len
Previously, you have used the count operator to count records.
Similarly, you can use the sum operator to add (sum) the values of a
specific field from a group of records. As in the case of count, the
result of a sum is retrieved via the storage object:
>>> sum = db.log.severity.sum()
>>> print(db().select(sum).first()[sum])
6
You can also use avg, min, and max to the average, minimum,
and maximum value respectively for the selected records. For example:
>>> max = db.log.severity.max()
>>> print(db().select(max).first()[max])
3
len computes the length of field’s value. It is generally used on
string or text fields but depending on the back-end it may still work
for other types too (boolean, integer, etc).
>>> for row in db(db.log.event.len() > 13).select():
... print(row.event)
...
unauthorized login
Expressions can be combined to form more complex expressions. For example here we are computing the sum of the length of the event strings in the logs plus one:
>>> exp = (db.log.event.len() + 1).sum()
>>> db().select(exp).first()[exp]
43
Substrings
One can build an expression to refer to a substring. For example, we can group things whose name starts with the same three characters and select only one from each group:
db(db.thing).select(distinct = db.thing.name[:3])
Default values with coalesce and coalesce_zero
There are times when you need to pull a value from database but also
need a default values if the value for a record is set to NULL. In SQL
there is a function, COALESCE, for this. py4web has an equivalent
coalesce method:
>>> db.define_table('sysuser', Field('username'), Field('fullname'))
<Table sysuser (id, username, fullname)>
>>> db.sysuser.insert(username='max', fullname='Max Power')
1
>>> db.sysuser.insert(username='tim', fullname=None)
2
>>> coa = db.sysuser.fullname.coalesce(db.sysuser.username)
>>> for row in db().select(coa):
... print(row[coa])
...
Max Power
tim
Other times you need to compute a mathematical expression but some
fields have a value set to None while it should be zero.
coalesce_zero comes to the rescue by defaulting None to zero in the
query:
>>> db.define_table('sysuser', Field('username'), Field('points'))
<Table sysuser (id, username, points)>
>>> db.sysuser.insert(username='max', points=10)
1
>>> db.sysuser.insert(username='tim', points=None)
2
>>> exp = db.sysuser.points.coalesce_zero().sum()
>>> db().select(exp).first()[exp]
10
>>> type(exp)
<class 'pydal.objects.Expression'>
>>> print(exp)
SUM(COALESCE("sysuser"."points",'0'))
Exporting and importing data
CSV (one Table at a time)
When a Rows object is converted to a string it is automatically serialized in CSV:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> print(rows)
person.id,person.name,thing.id,thing.name,thing.owner_id
1,Alex,1,Boat,1
1,Alex,2,Chair,1
2,Bob,3,Shoes,2
You can serialize a single table in CSV and store it in a file “test.csv”:
with open('test.csv', 'wb') as dumpfile:
dumpfile.write(str(db(db.person).select()))
Converting a Rows object into a string produces an encoded binary string
and it’s better to be explicit with the encoding used:
with open('test.csv', 'w', encoding='utf-8', newline='') as dumpfile:
dumpfile.write(str(db(db.person).select()))
This is equivalent to
rows = db(db.person).select()
with open('test.csv', 'wb') as dumpfile:
rows.export_to_csv_file(dumpfile)
You can read the CSV file back with:
with open('test.csv', 'rb') as dumpfile:
db.person.import_from_csv_file(dumpfile)
Again, you can be explict about the encoding for the exporting file:
rows = db(db.person).select()
with open('test.csv', 'w', encoding='utf-8', newline='') as dumpfile:
rows.export_to_csv_file(dumpfile)
and the importing one:
with open('test.csv', 'r', encoding='utf-8', newline='') as dumpfile:
db.person.import_from_csv_file(dumpfile)
When importing, py4web looks for the field names in the CSV header. In this example, it finds two columns: “person.id” and “person.name”. It ignores the “person.” prefix, and it ignores the “id” fields. Then all records are appended and assigned new ids.
CSV (all tables at once)
In py4web, you can backup/restore an entire database with two commands:
To export:
with open('somefile.csv', 'w', encoding='utf-8', newline='') as dumpfile:
db.export_to_csv_file(dumpfile)
To import:
with open('somefile.csv', 'r', encoding='utf-8', newline='') as dumpfile:
db.import_from_csv_file(dumpfile)
This mechanism can be used even if the importing database is of a different type than the exporting database.
The data is stored in “somefile.csv” as a CSV file where each table starts with one line that indicates the tablename, and another line with the fieldnames:
TABLE tablename
field1,field2,field3,...
Two tables are separated by \r\n\r\n (that is two empty lines). The
file ends with the line
END
The file does not include uploaded files if these are not stored in the database. The upload files stored on filesystem must be dumped separately, a zip of the “uploads” folder may suffice in most cases.
When importing, the new records will be appended to the database if it is not empty. In general the new imported records will not have the same record id as the original (saved) records but py4web will restore references so they are not broken, even if the id values may change.
If a table contains a field called uuid, this field will be used to
identify duplicates. Also, if an imported record has the same uuid
as an existing record, the previous record will be updated.
CSV and remote database synchronization
Consider once again the following model:
db.define_table('person',
Field('name'))
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
# usage example
if db(db.person).isempty():
nid = db.person.insert(name='Massimo')
db.thing.insert(name='Chair', owner_id=nid)
Each record is identified by an identifier and referenced by that id. If you have two copies of the database used by distinct py4web installations, the id is unique only within each database and not across the databases. This is a problem when merging records from different databases.
In order to make records uniquely identifiable across databases, they must: - have a unique id (UUID), - have a last modification time to track the most recent among multiple copies, - reference the UUID instead of the id.
This can be achieved changing the above model into:
import datetime
import uuid
now = datetime.datetime.utcnow
db.define_table('person',
Field('uuid', length=64),
Field('modified_on', 'datetime', default=now, update=now),
Field('name'))
db.define_table('thing',
Field('uuid', length=64),
Field('modified_on', 'datetime', default=now, update=now),
Field('name'),
Field('owner_id', length=64))
db.person.uuid.default = db.thing.uuid.default = lambda:str(uuid.uuid4())
db.thing.owner_id.requires = IS_IN_DB(db, 'person.uuid', '%(name)s')
# usage example
if db(db.person).isempty():
nid = str(uuid.uuid4())
db.person.insert(uuid=nid, name='Massimo')
db.thing.insert(name='Chair', owner_id=nid)
Notice that in the above table definitions, the default value for the two
uuidfields is set to a lambda function, which returns a UUID (converted to a string). The lambda function is called once for each record inserted, ensuring that each record gets a unique UUID, even if multiple records are inserted in a single transaction.
Create a controller action to export the database:
from py4web import response
def export():
s = StringIO.StringIO()
db.export_to_csv_file(s)
response.set_header('Content-Type', 'text/csv')
return s.getvalue()
Create a controller action to import a saved copy of the other database and sync records:
from yatl.helpers import FORM, INPUT
def import_and_sync():
form = FORM(INPUT(_type='file', _name='data'), INPUT(_type='submit'))
if form.process().accepted:
db.import_from_csv_file(form.vars.data.file, unique=False)
# for every table
for tablename in db.tables:
table = db[tablename]
# for every uuid, delete all but the latest
items = db(table).select(table.id, table.uuid,
orderby=~table.modified_on,
groupby=table.uuid)
for item in items:
db((table.uuid == item.uuid) & (table.id != item.id)).delete()
return dict(form=form)
Optionally you should create an index manually to make the search by uuid faster.
Alternatively, you can use XML-RPC to export/import the file.
If the records reference uploaded files, you also need to export/import the content of the uploads folder. Notice that files therein are already labeled by UUIDs so you do not need to worry about naming conflicts and references.
HTML and XML (one Table at a time)
Rows objects also have an xml method (like helpers) that serializes
it to XML/HTML:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> print(rows.xml())
<table>
<thead>
<tr><th>person.id</th><th>person.name</th>
<th>thing.id</th><th>thing.name</th>
<th>thing.owner_id</th>
</tr>
</thead>
<tbody>
<tr class="w2p_odd odd">
<td>1</td><td>Alex</td>
<td>1</td><td>Boat</td>
<td>1</td>
</tr>
<tr class="w2p_even even">
<td>1</td><td>Alex</td>
<td>2</td><td>Chair</td>
<td>1</td>
</tr>
<tr class="w2p_odd odd">
<td>2</td><td>Bob</td>
<td>3</td>
<td>Shoes</td>
<td>2</td>
</tr>
</tbody>
</table>
If you need to serialize the Rows in any other XML format with custom
tags, you can easily do that using the universal TAG XML helper
that we’ll see later and the Python syntax
*<iterable> allowed in function calls:
>>> rows = db(db.person).select()
>>> print(TAG.result(*[TAG.row(*[TAG.field(r[f], _name=f) for f in db.person.fields]) for r in rows]))
<result>
<row><field name="id">1</field><field name="name">Alex</field></row>
<row><field name="id">2</field><field name="name">Bob</field></row>
<row><field name="id">3</field><field name="name">Carl</field></row>
</result>
Warning
Do not confuse the TAG XML helper used here (see the TAG
chapter) with the Tags method that will be extensively explained
on the Authorization using Tags chapter.
Data representation
The Rows.export_to_csv_file method accepts a keyword argument named
represent. When True it will use the columns represent
function while exporting the data instead of the raw data.
The function also accepts a keyword argument named colnames that
should contain a list of column names one wish to export. It defaults to
all columns.
Both export_to_csv_file and import_from_csv_file accept keyword
arguments that tell the csv parser the format to save/load the files: -
delimiter: delimiter to separate values (default ‘,’) -
quotechar: character to use to quote string values (default to
double quotes) - quoting: quote system (default
csv.QUOTE_MINIMAL)
Here is some example usage:
import csv
rows = db(query).select()
with open('/tmp/test.txt', 'wb') as oufile:
rows.export_to_csv_file(oufile,
delimiter='|',
quotechar='"',
quoting=csv.QUOTE_NONNUMERIC)
Which would render something similar to
"hello"|35|"this is the text description"|"2013-03-03"
For more information consult the official Python documentation
Advanced features
list:<type> and contains
py4web provides the following special field types:
list:string
list:integer
list:reference <table>
They can contain lists of strings, of integers and of references respectively.
On Google App Engine NoSQL list:string is mapped into
StringListProperty, the other two are mapped into
ListProperty(int). On relational databases they are mapped into text
fields which contain the list of items separated by |. For example
[1, 2, 3] is mapped into |1|2|3|.
For lists of string the items are escaped so that any | in the item
is replaced by a ||. Anyway this is an internal representation and
it is transparent to the user.
You can use list:string, for example, in the following way:
>>> db.define_table('product',
... Field('name'),
... Field('colors', 'list:string'))
<Table product (id, name, colors)>
>>> db.product.colors.requires = IS_IN_SET(('red', 'blue', 'green'))
>>> db.product.insert(name='Toy Car', colors=['red', 'green'])
1
>>> products = db(db.product.colors.contains('red')).select()
>>> for item in products:
... print(item.name, item.colors)
...
Toy Car ['red', 'green']
list:integer works in the same way but the items must be integers.
As usual the requirements are enforced at the level of forms, not at the
level of insert.
For
list:<type>fields thecontains(value)operator maps into a non trivial query that checks for lists containing thevalue. Thecontainsoperator also works for regularstringandtextfields and it maps into aLIKE '%value%'.
The list:reference and the contains(value) operator are
particularly useful to de-normalize many-to-many relations. Here is an
example:
>>> db.define_table('tag',
... Field('name'),
... format='%(name)s')
<Table tag (id, name)>
>>> db.define_table('product',
... Field('name'),
... Field('tags', 'list:reference tag'))
<Table product (id, name, tags)>
>>> a = db.tag.insert(name='red')
>>> b = db.tag.insert(name='green')
>>> c = db.tag.insert(name='blue')
>>> db.product.insert(name='Toy Car', tags=[a, b, c])
1
>>> products = db(db.product.tags.contains(b)).select()
>>> for item in products:
... print(item.name, item.tags)
...
Toy Car [1, 2, 3]
>>> for item in products:
... print(item.name, db.product.tags.represent(item.tags))
...
Toy Car red, green, blue
Notice that a list:reference tag field get a default constraint
requires = IS_IN_DB(db, db.tag._id, db.tag._format, multiple=True)
that produces a SELECT/OPTION multiple drop-box in forms.
Also notice that this field gets a default represent attribute which
represents the list of references as a comma-separated list of formatted
references. This is used in read forms.
While
list:referencehas a default validator and a default representation,list:integerandlist:stringdo not. So these two need anIS_IN_SETor anIS_IN_DBvalidator if you want to use them in forms.
Table inheritance
It is possible to create a table that contains all the fields from
another table. It is sufficient to pass the other table in place of a
field to define_table. For example
>>> db.define_table('person', Field('name'), Field('gender'))
<Table person (id, name, gender)>
>>> db.define_table('doctor', db.person, Field('specialization'))
<Table doctor (id, name, gender, specialization)>
It is also possible to define a dummy table that is not stored in a database in order to reuse it in multiple other places. For example:
now = datetime.datetime.utcnow
signature = db.Table(db, 'signature',
Field('is_active', 'boolean', default=True),
Field('created_on', 'datetime', default=now),
Field('created_by', db.auth_user, default=auth.user_id),
Field('modified_on', 'datetime', update=now),
Field('modified_by', db.auth_user, update=auth.user_id))
db.define_table('payment', Field('amount', 'double'), signature)
This example assumes that standard py4web authentication is enabled.
Notice that if you use Auth py4web already creates one such table
for you:
auth = Auth(db)
db.define_table('payment', Field('amount', 'double'), auth.signature)
When using table inheritance, if you want the inheriting table to inherit validators, be sure to define the validators of the parent table before defining the inheriting table.
filter_in and filter_out
It is possible to define a filter for each field to be called before a value is inserted into the database for that field and after a value is retrieved from the database.
Imagine for example that you want to store a serializable Python data structure in a field in the JSON format. Here is how it could be accomplished:
>>> import json
>>> db.define_table('anyobj',
... Field('name'),
... Field('data', 'text'))
<Table anyobj (id, name, data)>
>>> db.anyobj.data.filter_in = lambda obj: json.dumps(obj)
>>> db.anyobj.data.filter_out = lambda txt: json.loads(txt)
>>> myobj = ['hello', 'world', 1, {2: 3}]
>>> aid = db.anyobj.insert(name='myobjname', data=myobj)
>>> row = db.anyobj[aid]
>>> row.data
['hello', 'world', 1, {'2': 3}]
Another way to accomplish the same is by using a Field of type
SQLCustomType, as discussed in Custom Field types.
callbacks on record insert, delete and update
PY4WEB provides a mechanism to register callbacks to be called before and/or after insert, update and delete of records.
Each table stores six lists of callbacks:
db.mytable._before_insert
db.mytable._after_insert
db.mytable._before_update
db.mytable._after_update
db.mytable._before_delete
db.mytable._after_delete
You can register a callback function by appending it to the corresponding list. The caveat is that depending on the functionality, the callback has different signature.
This is best explained by examples.
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> def pprint(callback, *args):
... print("%s%s" % (callback, args))
...
>>> db.person._before_insert.append(lambda f: pprint('before_insert', f))
>>> db.person._after_insert.append(lambda f, i: pprint('after_insert', f, i))
>>> db.person.insert(name='John')
before_insert(<OpRow {'name': 'John'}>,)
after_insert(<OpRow {'name': 'John'}>, 1)
1
>>> db.person._before_update.append(lambda s, f: pprint('before_update', s, f))
>>> db.person._after_update.append(lambda s, f: pprint('after_update', s, f))
>>> db(db.person.id == 1).update(name='Tim')
before_update(<Set ("person"."id" = 1)>, <OpRow {'name': 'Tim'}>)
after_update(<Set ("person"."id" = 1)>, <OpRow {'name': 'Tim'}>)
1
>>> db.person._before_delete.append(lambda s: pprint('before_delete', s))
>>> db.person._after_delete.append(lambda s: pprint('after_delete', s))
>>> db(db.person.id == 1).delete()
before_delete(<Set ("person"."id" = 1)>,)
after_delete(<Set ("person"."id" = 1)>,)
1
As you can see: - f gets passed the OpRow object with data for
insert or update. - i gets passed the id of the newly inserted
record. - s gets passed the Set object used for update or
delete. OpRow is an helper object specialized in storing (field,
value) pairs, you can think of it as a normal dictionary that you can
use even with the syntax of attribute notation (that is f.name and
f['name'] are equivalent).
The return values of these callback should be None or False. If
any of the _before_* callback returns a True value it will abort
the actual insert/update/delete operation.
Some times a callback may need to perform an update in the same or a different table and one wants to avoid firing other callbacks, which could cause an infinite loop.
For this purpose there the Set objects have an update_naive
method that works like update but ignores before and after
callbacks.
Database cascades
Database schema can define relationships which trigger deletions of related records, known as cascading. The DAL is not informed when a record is deleted due to a cascade. So no *_delete callback will ever be called as consequence of a cascade-deletion.
Record versioning
It is possible to ask py4web to save every copy of a record when the record is individually modified. There are different ways to do it and it can be done for all tables at once using the syntax:
auth.enable_record_versioning(db)
this requires Auth. It can also be done for each individual table as
discussed below.
Consider the following table:
db.define_table('stored_item',
Field('name'),
Field('quantity', 'integer'),
Field('is_active', 'boolean',
writable=False, readable=False, default=True))
Notice the hidden boolean field called is_active and defaulting to
True.
We can tell py4web to create a new table (in the same or a different database) and store all previous versions of each record in the table, when modified.
This is done in the following way:
db.stored_item._enable_record_versioning()
or in a more verbose syntax:
db.stored_item._enable_record_versioning(archive_db=db,
archive_name='stored_item_archive',
current_record='current_record',
is_active='is_active')
The archive_db=db tells py4web to store the archive table in the
same database as the stored_item table. The archive_name sets
the name for the archive table. The archive table has the same fields as
the original table stored_item except that unique fields are no
longer unique (because it needs to store multiple versions) and has an
extra field which name is specified by current_record and which is a
reference to the current record in the stored_item table.
When records are deleted, they are not really deleted. A deleted record
is copied in the stored_item_archive table (like when it is
modified) and the is_active field is set to False. By enabling
record versioning py4web sets a common_filter on this table that
hides all records in table stored_item where the is_active field
is set to False. The is_active parameter in the
_enable_record_versioning method allows to specify the name of the
field used by the common_filter to determine if the field was
deleted or not.
Common filters
A common filter is a generalization of the above multi-tenancy idea. It provides an easy way to prevent repeating of the same query. Consider for example the following table:
db.define_table('blog_post',
Field('subject'),
Field('post_text', 'text'),
Field('is_public', 'boolean'),
common_filter = lambda query: db.blog_post.is_public == True)
Any select, delete or update in this table, will include only public blog posts. The attribute can also be modified at runtime:
db.blog_post._common_filter = lambda query: ...
It serves both as a way to avoid repeating the “db.blog_post.is_public==True” phrase in each blog post search, and also as a security enhancement, that prevents you from forgetting to disallow viewing of non-public posts.
In case you actually do want items left out by the common filter (for example, allowing the admin to see non-public posts), you can either remove the filter:
db.blog_post._common_filter = None
or ignore it:
db(query, ignore_common_filters=True)
Note that common_filters are ignored by the appadmin interface.
Custom Field types
Aside for using filter_in and filter_out, it is possible to
define new/custom field types. For example, suppose that you want to
define a custom type to store an IP address:
>>> def ip2int(sv):
... "Convert an IPV4 to an integer."
... sp = sv.split('.'); assert len(sp) == 4 # IPV4 only
... iip = 0
... for i in map(int, sp): iip = (iip<<8) + i
... return iip
...
>>> def int2ip(iv):
... "Convert an integer to an IPV4."
... assert iv > 0
... iv = (iv,); ov = []
... for i in range(3):
... iv = divmod(iv[0], 256)
... ov.insert(0, iv[1])
... ov.insert(0, iv[0])
... return '.'.join(map(str, ov))
...
>>> from pydal import SQLCustomType
>>> ipv4 = SQLCustomType(type='string', native='integer',
... encoder=lambda x : str(ip2int(x)), decoder=int2ip)
>>> db.define_table('website',
... Field('name'),
... Field('ipaddr', type=ipv4))
<Table website (id, name, ipaddr)>
>>> db.website.insert(name='wikipedia', ipaddr='91.198.174.192')
1
>>> db.website.insert(name='google', ipaddr='172.217.11.174')
2
>>> db.website.insert(name='youtube', ipaddr='74.125.65.91')
3
>>> db.website.insert(name='github', ipaddr='207.97.227.239')
4
>>> rows = db(db.website.ipaddr > '100.0.0.0').select(orderby=~db.website.ipaddr)
>>> for row in rows:
... print(row.name, row.ipaddr)
...
github 207.97.227.239
google 172.217.11.174
SQLCustomType is a field type factory. Its type argument must be
one of the standard py4web types. It tells py4web how to treat the field
values at the py4web level. native is the type of the field as far
as the database is concerned. Allowed names depend on the database
engine. encoder is an optional transformation function applied when
the data is stored and decoder is the optional reverse
transformation function.
This feature is marked as experimental because can make your code not portable across database engines.
It does not work on Google App Engine NoSQL.
Using DAL without define tables
The DAL can be used from any Python program simply by doing this:
from pydal import DAL, Field
db = DAL('sqlite://storage.sqlite', folder='path/to/app/databases')
i.e. import the DAL, connect and specify the folder which contains the .table files (the app/databases folder).
To access the data and its attributes we still have to define all the
tables we are going to access with db.define_table.
If we just need access to the data but not to the py4web table attributes, we get away without re-defining the tables but simply asking py4web to read the necessary info from the metadata in the .table files:
from py4web import DAL, Field
db = DAL('sqlite://storage.sqlite', folder='path/to/app/databases', auto_import=True)
This allows us to access any db.table without need to re-define it.
Distributed transaction
At the time of writing this feature is only supported by PostgreSQL, MySQL and Firebird, since they expose API for two-phase commits.
Assuming you have two (or more) connections to distinct PostgreSQL databases, for example:
db_a = DAL('postgres://...')
db_b = DAL('postgres://...')
In your models or controllers, you can commit them concurrently with:
DAL.distributed_transaction_commit(db_a, db_b)
On failure, this function rolls back and raises an Exception.
In controllers, when one action returns, if you have two distinct connections and you do not call the above function, py4web commits them separately. This means there is a possibility that one of the commits succeeds and one fails. The distributed transaction prevents this from happening.
Copy data from one db into another
Consider the situation in which you have been using the following database:
db = DAL('sqlite://storage.sqlite')
and you wish to move to another database using a different connection string:
db = DAL('postgres://username:password@localhost/mydb')
Before you switch, you want to move the data and rebuild all the metadata for the new database. We assume the new database to exist but we also assume it is empty.
Gotchas
Note on new DAL and adapters
The source code of the Database Abstraction Layer was completely rewritten in 2010. While it stays backward compatible, the rewrite made it more modular and easier to extend. Here we explain the main logic.
The module “dal.py” defines, among other, the following classes.
ConnectionPool
BaseAdapter extends ConnectionPool
Row
DAL
Reference
Table
Expression
Field
Query
Set
Rows
Their use has been explained in the previous sections, except for
BaseAdapter. When the methods of a Table or Set object need
to communicate with the database they delegate to methods of the adapter
the task to generate the SQL and or the function call.
For example:
db.mytable.insert(myfield='myvalue')
calls
Table.insert(myfield='myvalue')
which delegates the adapter by returning:
db._adapter.insert(db.mytable, db.mytable._listify(dict(myfield='myvalue')))
Here db.mytable._listify converts the dict of arguments into a list
of (field,value) and calls the insert method of the adapter.
db._adapter does more or less the following:
query = db._adapter._insert(db.mytable, list_of_fields)
db._adapter.execute(query)
where the first line builds the query and the second executes it.
BaseAdapter defines the interface for all adapters.
pyDAL at the moment of writing this book, contains the following adapters:
SQLiteAdapter extends BaseAdapter
JDBCSQLiteAdapter extends SQLiteAdapter
MySQLAdapter extends BaseAdapter
PostgreSQLAdapter extends BaseAdapter
JDBCPostgreSQLAdapter extends PostgreSQLAdapter
OracleAdapter extends BaseAdapter
MSSQLAdapter extends BaseAdapter
MSSQL2Adapter extends MSSQLAdapter
MSSQL3Adapter extends MSSQLAdapter
MSSQL4Adapter extends MSSQLAdapter
FireBirdAdapter extends BaseAdapter
FireBirdEmbeddedAdapter extends FireBirdAdapter
InformixAdapter extends BaseAdapter
DB2Adapter extends BaseAdapter
IngresAdapter extends BaseAdapter
IngresUnicodeAdapter extends IngresAdapter
GoogleSQLAdapter extends MySQLAdapter
NoSQLAdapter extends BaseAdapter
GoogleDatastoreAdapter extends NoSQLAdapter
CubridAdapter extends MySQLAdapter (experimental)
TeradataAdapter extends DB2Adapter (experimental)
SAPDBAdapter extends BaseAdapter (experimental)
CouchDBAdapter extends NoSQLAdapter (experimental)
IMAPAdapter extends NoSQLAdapter (experimental)
MongoDBAdapter extends NoSQLAdapter (experimental)
VerticaAdapter extends MSSQLAdapter (experimental)
SybaseAdapter extends MSSQLAdapter (experimental)
which override the behavior of the BaseAdapter.
Each adapter has more or less this structure:
class MySQLAdapter(BaseAdapter):
# specify a driver to use
driver = globals().get('pymysql', None)
# map py4web types into database types
types = {
'boolean': 'CHAR(1)',
'string': 'VARCHAR(%(length)s)',
'text': 'LONGTEXT',
...
}
# connect to the database using driver
def __init__(self, db, uri, pool_size=0, folder=None, db_codec ='UTF-8',
credential_decoder=lambda x:x, driver_args={},
adapter_args={}):
# parse uri string and store parameters in driver_args
...
# define a connection function
def connect(driver_args=driver_args):
return self.driver.connect(**driver_args)
# place it in the pool
self.pool_connection(connect)
# set optional parameters (after connection)
self.execute('SET FOREIGN_KEY_CHECKS=1;')
self.execute("SET sql_mode='NO_BACKSLASH_ESCAPES';")
# override BaseAdapter methods as needed
def lastrowid(self, table):
self.execute('select last_insert_id();')
return int(self.cursor.fetchone()[0])
Looking at the various adapters as example should be easy to write new ones.
When db instance is created:
db = DAL('mysql://...')
the prefix in the uri string defines the adapter. The mapping is defined in the following dictionary also in “dal.py”:
couchdb |
pydal.adapters.couchdb.CouchDB |
cubrid |
pydal.adapters.mysql.Cubrid |
db2:ibm_db_dbi |
pydal.adapters.db2.DB2IBM |
db2:pyodbc |
pydal.adapters.db2.DB2Pyodbc |
firebird |
pydal.adapters.firebird.FireBird |
firebird_embedded |
pydal.adapters.firebird.FireBirdEmbedded |
google:MySQLdb |
pydal.adapters.google.GoogleMySQL |
google:datastore |
pydal.adapters.google.GoogleDatastore |
google:datastore+ndb |
pydal.adapters.google.GoogleDatastore |
google:psycopg2 |
pydal.adapters.google.GooglePostgres |
google:sql |
pydal.adapters.google.GoogleSQL |
informix |
pydal.adapters.informix.Informix |
informix-se |
pydal.adapters.informix.InformixSE |
ingres |
pydal.adapters.ingres.Ingres |
ingresu |
pydal.adapters.ingres.IngresUnicode |
pydal.adapters.postgres.JDBCPostgre |
|
pydal.adapters.sqlite.JDBCSQLite |
|
pydal.adapters.sqlite.JDBCSQLite |
|
mongodb |
pydal.adapters.mongo.Mongo |
mssql |
pydal.adapters.mssql.MSSQL1 |
mssql2 |
pydal.adapters.mssql.MSSQL1N |
mssql3 |
pydal.adapters.mssql.MSSQL3 |
mssql3n |
pydal.adapters.mssql.MSSQL3N |
mssql4 |
pydal.adapters.mssql.MSSQL4 |
mssql4n |
pydal.adapters.mssql.MSSQL4N |
mssqln |
pydal.adapters.mssql.MSSQL1N |
mysql |
pydal.adapters.mysql.MySQL |
oracle |
pydal.adapters.oracle.Oracle |
postgres |
pydal.adapters.postgres.Postgre |
postgres2 |
pydal.adapters.postgres.PostgreNew |
postgres2:psycopg2 |
pydal.adapters.postgres.PostgrePsycoNew |
postgres3 |
pydal.adapters.postgres.PostgreBoolean |
postgres3:psycopg2 |
pydal.adapters.postgres.PostgrePsycoBoolean |
postgres:psycopg2 |
pydal.adapters.postgres.PostgrePsyco |
pytds |
pydal.adapters.mssql.PyTDS |
sapdb |
pydal.adapters.sap.SAPDB |
spatialite |
pydal.adapters.sqlite.Spatialite |
spatialite:memory |
pydal.adapters.sqlite.Spatialite |
sqlite |
pydal.adapters.sqlite.SQLite |
sqlite:memory |
pydal.adapters.sqlite.SQLite |
sybase |
pydal.adapters.mssql.Sybase |
teradata |
pydal.adapters.teradata.Teradata |
vertica |
pydal.adapters.mssql.Vertica |
the uri string is then parsed in more detail by the adapter itself. An updated list of adapters can be obtained as dictionary with
For any adapter you can replace the driver with a different one globally (not thread safe):
import MySQLdb as mysqldb
from pydal.adapters.mysql import SQLAdapter
SQLAdapter.driver = mysqldb
i.e. mysqldb has to be that module with a .connect() method. You
can specify optional driver arguments and adapter arguments:
db = DAL(..., driver_args={}, adapter_args={})
For recognized adapters you can also simply specify the name in the
adapter_args:
from pydal.adapters.mysql import MySQL
assert "mysqldv" in MySQL.drivers
db = DAL(..., driver_args={}, adapter_args={"driver": "mysqldb"})
SQLite
SQLite does not support dropping and altering columns. That means that
py4web migrations will work up to a point. If you delete a field from a
table, the column will remain in the database but will be invisible to
py4web. If you decide to reinstate the column, py4web will try re-create
it and fail. In this case you must set fake_migrate=True so that
metadata is rebuilt without attempting to add the column again. Also,
for the same reason, SQLite is not aware of any change of column
type. If you insert a number in a string field, it will be stored as
string. If you later change the model and replace the type “string” with
type “integer”, SQLite will continue to keep the number as a string and
this may cause problem when you try to extract the data.
SQLite doesn’t have a boolean type. py4web internally maps booleans to a 1 character string, with ‘T’ and ‘F’ representing True and False. The DAL handles this completely; the abstraction of a true boolean value works well. But if you are updating the SQLite table with SQL directly, be aware of the py4web implementation, and avoid using 0 and 1 values.
MySQL
MySQL does not support multiple ALTER TABLE within a single transaction.
This means that any migration process is broken into multiple commits.
If something happens that causes a failure it is possible to break a
migration (the py4web metadata are no longer in sync with the actual
table structure in the database). This is unfortunate but it can be
prevented (migrate one table at the time) or it can be fixed in the
aftermath (revert the py4web model to what corresponds to the table
structure in database, set fake_migrate=True and after the metadata
has been rebuilt, set fake_migrate=False and migrate the table
again).
Google SQL
Google SQL has the same problems as MySQL and more. In particular table
metadata itself must be stored in the database in a table that is not
migrated by py4web. This is because Google App Engine has a read-only
file system. PY4WEB migrations in Google SQL combined with the MySQL
issue described above can result in metadata corruption. Again, this can
be prevented (by migrating the table at once and then setting
migrate=False so that the metadata table is not accessed any more) or it
can fixed in the aftermath (by accessing the database using the Google
dashboard and deleting any corrupted entry from the table called
py4web_filesystem.
MSSQL (Microsoft SQL Server)
MSSQL < 2012 does not support the SQL OFFSET keyword. Therefore the
database cannot do pagination. When doing a limitby=(a, b) py4web
will fetch the first a + b rows and discard the first a. This
may result in a considerable overhead when compared with other database
engines. If you’re using MSSQL >= 2005, the recommended prefix to use is
mssql3:// which provides a method to avoid the issue of fetching the
entire non-paginated resultset. If you’re on MSSQL >= 2012, use
mssql4:// that uses the
OFFSET ... ROWS ... FETCH NEXT ... ROWS ONLY construct to support
natively pagination without performance hits like other backends. The
mssql:// uri also enforces (for historical reasons) the use of
text columns, that are superseeded in more recent versions (from
2005 onwards) by varchar(max). mssql3:// and mssql4://
should be used if you don’t want to face some limitations of the -
officially deprecated - text columns.
MSSQL has problems with circular references in tables that have ONDELETE CASCADE. This is an MSSQL bug and you work around it by setting the ondelete attribute for all reference fields to “NO ACTION”. You can also do it once and for all before you define tables:
db = DAL('mssql://....')
for key in db._adapter.types:
if ' ON DELETE %(on_delete_action)s' in db._adapter.types[key]:
db._adapter.types[key] = db._adapter.types[key].replace('%(on_delete_action)s', 'NO ACTION')
MSSQL also has problems with arguments passed to the DISTINCT keyword and therefore while this works,
db(query).select(distinct=True)
this does not
db(query).select(distinct=db.mytable.myfield)
Oracle
Oracle also does not support pagination. It does not support neither the
OFFSET nor the LIMIT keywords. PY4WEB achieves pagination by translating
a db(...).select(limitby=(a, b)) into a complex three-way nested
select (as suggested by official Oracle documentation). This works for
simple select but may break for complex selects involving aliased fields
and or joins.
Google NoSQL (Datastore)
Google NoSQL (Datastore) does not allow joins, left joins, aggregates, expression, OR involving more than one table, the ‘like’ operator searches in “text” fields.
Transactions are limited and not provided automatically by py4web (you
need to use the Google API run_in_transaction which you can look up
in the Google App Engine documentation online).
Google also limits the number of records you can retrieve in each one
query (1000 at the time of writing). On the Google datastore record IDs
are integer but they are not sequential. While on SQL the “list:string”
type is mapped into a “text” type, on the Google Datastore it is mapped
into a ListStringProperty. Similarly “list:integer” and
“list:reference” are mapped into ListProperty. This makes searches
for content inside these fields types more efficient on Google NoSQL
than on SQL databases.