The Database Abstraction Layer (DAL)
DAL introduction
py4web rely on a database abstraction layer (DAL), an API that maps Python objects into database objects such as queries, tables, and records. The DAL dynamically generates the SQL in real time using the specified dialect for the database back end, so that you do not have to write SQL code or learn different SQL dialects (the term SQL is used generically), and the application will be portable among different types of databases. The DAL choosen is a pure Python one called pyDAL. It was conceived in the web2py project but it’s a standard python module: you can use it in any Python context.
Nota
What makes pyDAL different from most of the other DALs is the syntax: it maps records to python dictionaries, which is simpler and closer to SQL. Other famous frameworks instead strictly rely on an Object Relational Mapping (ORM) like the Django ORM or the SQL Alchemy ORM, that maps tables to Python classes and rows to Objects.
A little taste of pyDAL features:
Transactions
Aggregates
Inner & Outer Joins
Nested Selects
Nota
An important difference between py4web and web2py is that only some few Field attributes are safe to modify in actions. See Thread safety and Field attributes for more info, and De web2py para py4web for a general list of differences.
Supported databases
A partial list of supported databases is show in the table below. Please check on the py4web/pyDAL web site and mailing list for more recent adapters.
Nota
In any modern python distribution SQLite is actually built-in as a Python library. The SQLite driver (sqlite3) is also included: you don’t need to install it. Hence this is the most popular database for testing and development.
The Windows and the Mac binary distribution work out of the box with SQLite and PostgreSQL only. To use any other database back end, run a full py4web distribution and install the appropriate driver for the required back end. Once the proper driver is installed, start py4web and it will automatically find the driver.
Here is a list of the drivers py4web can use:
Database |
Drivers (source) |
|---|---|
SQLite |
sqlite3 ou pySqlite2 ou zxJDBC (em Jython) |
PostgreSQL |
psycopg2 ou zxJDBC (em Jython) |
MySQL |
pymysql ou MySQLdb |
Oráculo |
cx_Oracle |
MSSQL |
pyodbc ou pypyodbc |
FireBird |
KInterbasDB ou FDB ou pyodbc |
DB2 |
pyodbc |
Informix |
informixdb |
Ingres |
ingresdbi |
CUBRID |
cubriddb |
Sybase |
Sybase |
Teradata |
pyodbc |
SAPDB |
sapdb |
MongoDB |
pymongo |
IMAP |
imaplib |
Support of MongoDB is experimental. Google NoSQL is treated as a particular case. The Gotchas section at the end of this chapter has some more information about specific databases.
The DAL: a quick tour
define py4web as seguintes classes que compõem o DAL:
- DAL
represents a database connection. For example:
db = DAL('sqlite://storage.sqlite')
- Table
represents a database table. You do not directly instantiate Table; instead,
DAL.define_tabledoes.db.define_table('mytable', Field('myfield'))
Os métodos mais importantes de uma tabela são:
`` Insert``, `` truncate``, `` drop``, e `` import_from_csv_file``.
- Field
represents a database field. It can be instantiated and passed as an argument to
DAL.define_table.- Rows
is the object returned by a database select. It can be thought of as a list of
Rowrows:rows = db(db.mytable.myfield != None).select()
- Row
contains field values:
for row in rows: print(row.myfield)
- Query
is an object that represents a SQL “where” clause:
myquery = (db.mytable.myfield != None) | (db.mytable.myfield > 'A')
- Set
is an object that represents a set of records. Its most important methods are
count,select,update, anddelete. For example:myset = db(myquery) rows = myset.select() myset.update(myfield='somevalue') myset.delete()
- Expression
is something like an
orderbyorgroupbyexpression. The Field class is derived from the Expression. Here is an example.myorder = db.mytable.myfield.upper() | db.mytable.id db().select(db.table.ALL, orderby=myorder)
Usando o DAL “stand-alone”
pyDAL is an independent python package. As such, it can be used
without the web2py/py4web environment; you just need to install
it with pip. Then import the pydal module when needed:
>>> from pydal import DAL, Field
Nota
Even if you can import modules directly from pydal, this is not
advisable from within py4web applications. Remember that py4web.DAL
is a fixture, pydal.DAL is not. In this context, the last command
should better be:
>>> from py4web import DAL, Field
Experimentar com o shell py4web
You can also experiment with the pyDAL API using the py4web shell, that is available using the Opção `` comando shell``.
Aviso
Mind that database changes may be persistent. So be careful and do NOT hesitate to create a new application for doing testing instead of tampering with an existing one. The only exception is the showcase db: in case of problems you can recreate it by simply deleting the database folder and restarting py4web. This will re-create the database with all the example data.
Note that most of the code snippets that contain the python prompt
>>> are also directly executable via a py4web shell.
This is a simple example, using the provided showcase app:
>>> from apps.showcase.examples.models import db
>>> db.tables()
['auth_user', 'auth_user_tag_groups', 'person', 'superhero', 'superpower', 'tag', 'thing', 'user_token', 'dummy']
>>> rows = db(db.superhero.name != None).select()
>>> rows.first()
<Row {'id': 1, 'tag': <Set ("tag"."superhero" = 1)>, 'name': 'Superman', 'real_identity': 1}>
You can also start by creating a connection from zero. For the sake of simplicity, you can use SQLite. Nothing in this discussion changes when you switch the back-end engine.
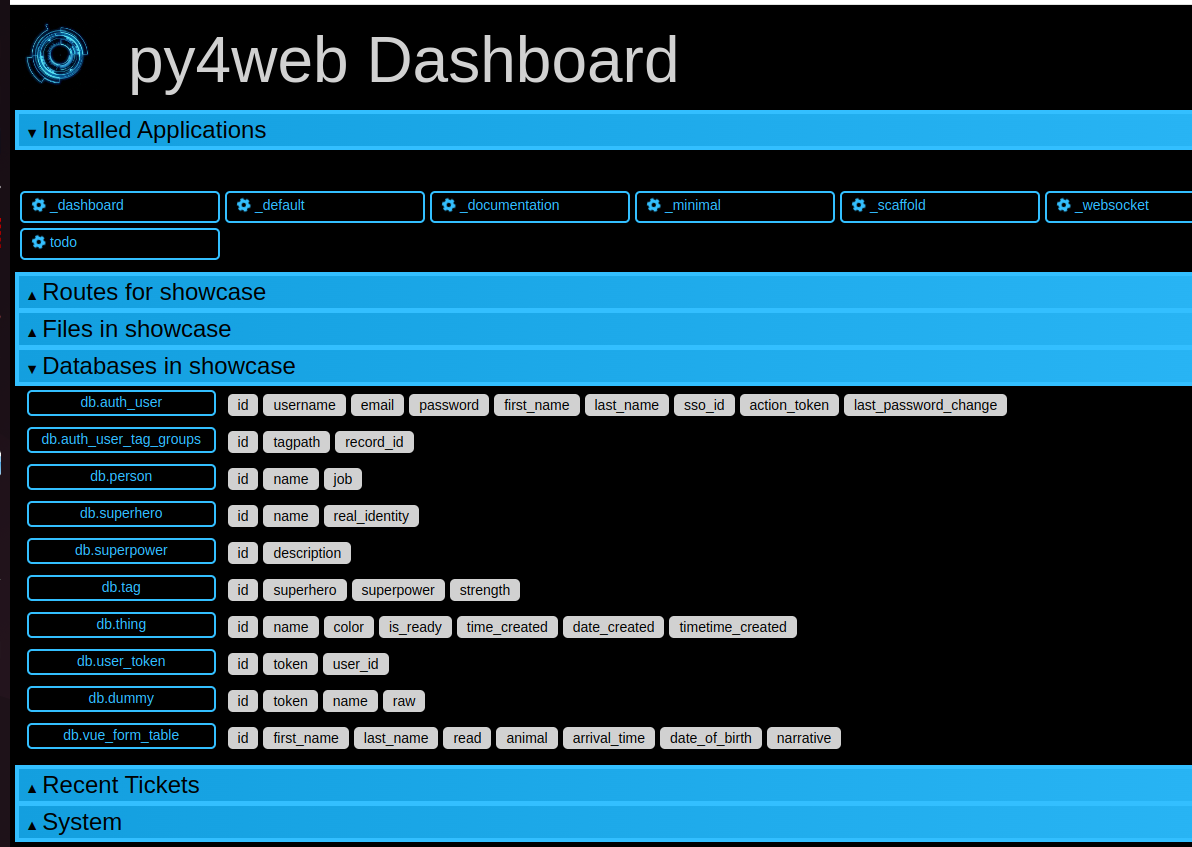
Using the dashboard app with databases
Generally you can use the dashboard app for viewing and modifying the databases of a particular app. However this is not bulletproof, so for security reason this by default is not applied to the showcase app. But if your installation is local (not exposed to public networks), you can enable it by simply adding to the file``apps/showcase/__init__.py`` the line:
from .examples.models import db
This allow you to look graphically inside the showcase application database:
Construtor DAL
Uso básico:
>>> db = DAL('sqlite://storage.sqlite')
O banco de dados agora está conectado e a conexão é armazenado na variável global `` db``.
A qualquer momento você pode recuperar a string de conexão.
>>> db._uri
sqlite://storage.sqlite
e o nome do banco
>>> db._dbname
sqlite
The connection string is called _uri because it is an instance of
a uniform resource identifier.
A DAL permite várias ligações com o mesmo banco de dados ou com diferentes bases de dados, mesmo bases de dados de diferentes tipos. Por enquanto, vamos supor a presença de um único banco de dados uma vez que esta é a situação mais comum.
Assinatura da DAL
DAL(uri='sqlite://dummy.db',
pool_size=0,
folder=None,
db_codec='UTF-8',
check_reserved=None,
migrate=True,
fake_migrate=False,
migrate_enabled=True,
fake_migrate_all=False,
decode_credentials=False,
driver_args=None,
adapter_args=None,
attempts=5,
auto_import=False,
bigint_id=False,
debug=False,
lazy_tables=False,
db_uid=None,
do_connect=True,
after_connection=None,
tables=None,
ignore_field_case=True,
entity_quoting=False,
table_hash=None)
Strings de conexão (o parâmetro uri)
Uma ligação com o banco de dados é estabelecida através da criação de uma instância do objecto DAL:
db = DAL('sqlite://storage.sqlite')
`` Db`` não é uma palavra-chave; é uma variável local que armazena o objeto de conexão `` DAL``. Você é livre para dar-lhe um nome diferente. O construtor de `` DAL`` requer um único argumento, a string de conexão. A seqüência de conexão é o único código py4web que depende de um banco de dados específico back-end. Aqui estão alguns exemplos de strings de conexão para tipos específicos de bancos de dados de back-end suportados (em todos os cases, assumimos o banco de dados está sendo executado a partir de localhost na sua porta padrão e é chamado de “teste”):
Database |
Connection string |
|---|---|
** ** SQLite |
`` SQLite: // storage.sqlite`` |
** ** MySQL |
|
** ** PostgreSQL |
|
** MSSQL (legado) ** |
`` Mssql: // username: password @ localhost / test`` |
** MSSQL (> = 2005) ** |
|
** MSSQL (> = 2012) ** |
|
** ** FireBird |
|
Oráculo |
`` Oracle: // username / password @ test`` |
** ** DB2 |
`` Db2: // username: password @ test`` |
** ** Ingres |
|
** ** Sybase |
|
** ** Informix |
`` Informix: // username: password @ test`` |
** ** Teradata |
|
** ** CUBRID |
|
** ** SAPDB |
`` Sapdb: // username: password @ localhost / test`` |
** ** IMAP |
`` Imap: // utilizador: senha @ servidor: port`` |
** ** MongoDB |
|
** Google / SQL ** |
`` Google: sql: // projecto: instance / database`` |
** Google / NoSQL ** |
`` Google: datastore`` |
** Google / NoSQL / NDB ** |
`` Google: armazenamento de dados + ndb`` |
in SQLite the database consists of a single file. If it does not exist, it is created. This file is locked every time it is accessed. In addition to the file “storage.sqlite” that contains the data, there will be also a sql.log file plus one additional file called longhash_tablename.table for every table definition. The table definition files are used during migrations; in case of problems they could be deleted (they’ll be automatically recreated).
in the case of MySQL, PostgreSQL, MSSQL, FireBird, Oracle, DB2, Ingres and Informix the database “test” must be created outside py4web. Once the connection is established, py4web will create, alter, and drop tables appropriately.
in the MySQL connection string, the
?set_encoding=utf8mb4at the end sets the encoding to UTF-8 and avoids anInvalid utf8 character string:error on Unicode characters that consist of four bytes, as by default, MySQL can only handle Unicode characters that consist of one to three bytes.in the Google/NoSQL case the
+ndboption turns on NDB. NDB uses a Memcache buffer to read data that is accessed often. This is completely automatic and done at the datastore level, not at the py4web level.it is also possible to set the connection string to
None. In this case DAL will not connect to any back-end database, but the API can still be accessed for testing.
Some times you may also need to generate SQL as if you had a connection but without actually connecting to the database. This can be done with
db = DAL('...', do_connect=False)
In this case you will be able to call _select, _insert,
_update, and _delete to generate SQL but not call select,
insert, update, and delete; see Generating raw SQL
for details. In most of the cases you can use
do_connect=False even without having the required database drivers.
Observe que, por padrão py4web usos utf8 codificação de caracteres para bancos de dados. Se você trabalha com bancos de dados que se comportam de forma diferente existente, você tem que mudá-lo com o parâmetro opcional `` db_codec`` como
db = DAL('...', db_codec='latin1')
Caso contrário, você vai ter bilhetes UnicodeDecodeError.
O pool de conexões
Um argumento comum do construtor DAL é a `` pool_size``; o padrão é zero.
As it is rather slow to establish a new database connection for each request, py4web implements a mechanism for connection pooling. Once a connection is established and the page has been served and the transaction completed, the connection is not closed but goes into a pool. When the next request arrives, py4web tries to recycle a connection from the pool and use that for the new transaction. If there are no available connections in the pool, a new connection is established.
Quando py4web começa, a piscina é sempre vazio. A piscina cresce até o mínimo entre o valor de `` pool_size`` e o número máximo de solicitações simultâneas. Isto significa que se `` POOL_SIZE = 10`` mas o nosso servidor nunca recebe mais de 5 solicitações simultâneas, em seguida, o tamanho real piscina só vai crescer a 5. Se `` POOL_SIZE = 0`` então o pool de conexão não é usada.
Conexões nas piscinas são compartilhados sequencialmente entre threads, no sentido de que eles podem ser usados por dois tópicos diferentes, mas não simultâneas. Há apenas uma piscina para cada processo py4web.
O parâmetro `` pool_size`` é ignorado pelo SQLite e Google App Engine. pool de conexão é ignorado para SQLite, uma vez que não daria qualquer benefício.
Falhas de conexão (parâmetro tentativas)
Se py4web não consegue se conectar ao banco de dados que espera 1 segundo e por tentativas padrão novamente até 5 vezes antes de declarar um fracasso. No case do pool de conexão, é possível que uma conexão em pool que permanece aberta, mas sem uso por algum tempo está fechado até o final de banco de dados. Graças à py4web recurso repetição tenta restabelecer essas ligações interrompidas. O número de tentativas é definido através do parâmetro tentativas.
Tabelas preguiçosos
Setting lazy_tables = True provides a major performance boost (but
not with py4web). It means that table creation is deferred until the
table is actually referenced.
Aviso
You should never use lazy tables in py4web. There is no advantage, no need, and possibly concurrency problems.
Aplicativos de modelo-less
Normally in py4web the code that define DAL tables lives in the file
models.py, hence it’s only executed at startup because it’s outside of actions.
However, it is possible to define DAL tables on demand inside actions. This is referred to as “model-less” development by the py4web community.
To use the “model-less” approach, you take responsibility for doing
all the housekeeping tasks. You call the table definitions when you
need them, and provide database connection passed as parameter.
Also, remember maintainability: other py4web developers expect to find
database definitions in the models.py file.
Bancos de dados replicados
The first argument of DAL(...) can be a list of URIs. In this case
py4web tries to connect to each of them. The main purpose for this is to
deal with multiple database servers and distribute the workload among
them. Here is a typical use case:
db = DAL(['mysql://...1', 'mysql://...2', 'mysql://...3'])
Neste case, as tentativas DAL para conectar-se a primeira e, em case de falha, ele vai tentar o segundo eo terceiro. Isto também pode ser utilizado para distribuir a carga em uma configuração de banco de dados mestre-escravo.
Palavras-chave reservadas
`` Check_reserved`` diz o construtor para verificar nomes de tabela e nomes de coluna contra palavras-chave reservada SQL em bancos de dados de back-end-alvo. `` padrões check_reserved`` a nenhum.
Esta é uma lista de strings que contêm os nomes de adaptador de banco de dados back-end.
The adapter name is the same as used in the DAL connection string. So if you want to check against PostgreSQL and MSSQL then your db connection would look as follows:
db = DAL('sqlite://storage.sqlite', check_reserved=['postgres', 'mssql'])
A DAL irá analisar as palavras-chave na mesma ordem da lista.
Existem duas opções extras “todos” e “comum”. Se você especificar tudo, ele irá verificar contra todas as palavras-chave SQL conhecidos. Se você especificar comum, ele só irá verificar contra palavras-chave SQL comuns, tais como `` SELECT``, `` INSERT``, `` update``, etc.
For supported back ends you may also specify if you would like to check
against the non-reserved SQL keywords as well. In this case you would
append _nonreserved to the name. For example:
check_reserved=['postgres', 'postgres_nonreserved']
Os seguintes backends de banco de dados suportar palavras reservadas verificação.
Database |
check_reserved |
|---|---|
** ** PostgreSQL |
`` Postgres (_nonreserved) `` |
** ** MySQL |
`` Mysql`` |
** ** FireBird |
`` Firebird (_nonreserved) `` |
** ** MSSQL |
`` mssql`` |
Oráculo |
`` oracle`` |
Configurações de quoting e case e do banco de dados
Citando de entidades SQL são ativadas por padrão em DAL, isto é:
`` Entity_quoting = True``
Desta forma, os identificadores são automaticamente citado em SQL gerado pelo DAL. No SQL palavras-chave de nível e identificadores não cotadas são maiúsculas e minúsculas, quoting assim uma SQL identificador torna maiúsculas de minúsculas.
Note-se que os identificadores não indicada deve sempre ser dobrado para minúsculas pelo motor de back-end acordo com a norma SQL, mas nem todos os motores estão em conformidade com o presente (por exemplo de dobragem PostgreSQL padrão é maiúsculas).
Por DAL padrão ignora case de campo também, para mudar este uso:
`` Ignore_field_case = False``
Para ter certeza de usar os mesmos nomes em python e no esquema DB, você deve organizar para ambas as configurações acima. Aqui está um exemplo:
db = DAL(ignore_field_case=False)
db.define_table('table1', Field('column'), Field('COLUMN'))
query = db.table1.COLUMN != db.table1.column
Fazendo uma conexão segura
Às vezes é necessário (e recomendado) para se conectar ao seu banco de dados usando conexão segura, especialmente se o seu banco de dados não está no mesmo servidor como a sua aplicação. Neste case, você precisa passar parâmetros adicionais para o driver de banco de dados. Você deve consultar a documentação do driver de banco de dados para obter detalhes.
Para PostgreSQL com psycopg2 ele deve ser parecido com isto:
DAL('postgres://user_name:user_password@server_addr/db_name',
driver_args={'sslmode': 'require', 'sslrootcert': 'root.crt',
'sslcert': 'postgresql.crt', 'sslkey': 'postgresql.key'})
onde os parâmetros `` sslrootcert``, `` sslcert`` e `` sslkey`` deve conter o caminho completo para os arquivos. Você deve consultar a documentação do PostgreSQL sobre como configurar o servidor PostgreSQL para aceitar conexões seguras.
Outros parâmetros do construtor DAL
Local de pasta do banco de dados
folder sets the place where migration files will be created (see
Migrations for details). By default it’s automatically set within py4web on the same
folder of the database itself, but you have to specify it when using DAL outside py4web.
Note that for SQLite databases it’s normally necessary, otherwise you’ll implicitly choose an in memory database (where folder and migrations don’t have any sense). So these constructors have the same meaning:
db = DAL('sqlite://storage.sqlite') # folder parameter not specified
db = DAL('sqlite:memory') # in memory database
Configurações padrão de migração
The DAL constructor migration settings are booleans affecting defaults and global behaviour (again, see Migrations for details)
`` Migrar = True`` define o comportamento de migração padrão para todas as tabelas
`` Fake_migrate = False`` define o comportamento fake_migrate padrão para todas as tabelas
`` Migrate_enabled = True`` se definido como desativa falsas todas as migrações
`` Fake_migrate_all = False`` Se definido como falso migra Verdadeiros todas as tabelas
`` `` commit`` e rollback``
The insert, truncate, delete, and update operations aren’t actually committed until py4web issues the commit command. The create and drop operations may be executed immediately, depending on the database engine.
If you pass db in an action.uses decorator, you don’t need to call
commit in the controller, it is automatically done for you (also, if you use
authenticated or unauthenticated decorator.)
Dica
always add db in an action.uses decorator (or use the
authenticated or unauthenticated decorator).
Otherwise you have to add db.commit() in every define_table and
in every table activities: insert(), update(), delete()
So in actions there is normally no need to ever call
commit or rollback explicitly in py4web unless you need more
granular control.
But if you executed commands via the shell, you are required to manually commit:
>>> db.commit()
Para verificar isso, vamos inserir um novo registro:
>>> db.person.insert(name="Bob")
2
and roll de volta, ou seja, ignorar todas as operações desde o último commit:
>>> db.rollback()
Se você agora inserir novamente, o contador voltará a ser definido para 2, desde a inserção anterior foi revertida.
>>> db.person.insert(name="Bob")
2
Code in models, views and controllers is enclosed in py4web code that looks like this (pseudo code):
try:
execute models, controller function and view
except:
rollback all connections
log the traceback
send a ticket to the visitor
else:
commit all connections
save cookies, sessions and return the page
Construtor Table
As tabelas são definidos na DAL via `` define_table``.
assinatura define_table
A assinatura para o método define_table é:
define_table(tablename, *fields, **kwargs)
Ele aceita um nome de tabela de preenchimento obrigatório e um número opcional de `` cases Field`` (mesmo nenhum). Você também pode passar um Table`` objeto (ou subclasse) `` em vez de um `` Field`` um, este clones e adiciona todos os campos (mas o “id”) com a tabela de definição. Outros argumentos de palavra-chave opcionais são: `` rname``, `` redefine``, `` common_filter``, `` fake_migrate``, `` fields``, `` format``, `` migrate``, `` on_define``, `` plural``, `` polymodel``, `` primarykey``, `` sequence_name``, `` singular``, `` table_class``, e `` trigger_name``, que são discutidos abaixo.
Por exemplo:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
Ele define, lojas e retorna um objeto `` Table`` chamado “pessoa” contendo um campo (coluna) “nome”. Este objeto também pode ser acessado via `` db.person``, assim você não precisa pegar o valor retornado pelo define_table.
`` Id``: Notas sobre a chave primária
Não declare um campo chamado “id”, porque um é criado por py4web de qualquer maneira. Cada tabela tem um campo chamado “id” por padrão. É um campo inteiro de auto-incremento (geralmente a partir de 1) utilizados para referência cruzada e para fazer cada registro original, assim que “id” é uma chave primária. (Nota: o contador id a partir de 1 é específico back-end Por exemplo, isto não se aplica ao Google App Engine NoSQL..)
Opcionalmente, você pode definir um campo de “type =” id”`` e py4web usará este campo como campo id auto-incremento. Isso não é recomendado, exceto quando acessar as tabelas de banco de dados legado que têm uma chave primária com um nome diferente. Com alguma limitação, você também pode usar diferentes chaves primárias usando o parâmetro ` primarykey``.
`` `` Plural`` e singular``
As pyDAL is a general DAL, it includes plural and singular attributes to refer to the table names so that external elements can use the proper name for a table.
`` Redefine``
As tabelas podem ser definidas apenas uma vez, mas você pode forçar py4web redefinir uma tabela existente:
db.define_table('person', Field('name'))
db.define_table('person', Field('name'), redefine=True)
A redefinição pode provocar uma migração se definição tabela muda.
`` Format``: representação da ficha
É opcional, mas recomendado para especificar uma representação formato para registros com o parâmetro `` format``.
db.define_table('person', Field('name'), format='%(name)s')
ou
db.define_table('person', Field('name'), format='%(name)s %(id)s')
ou mesmo os mais complexos usando uma função:
db.define_table('person', Field('name'),
format=lambda r: r.name or 'anonymous')
The format attribute will be used for two purposes:
To represent referenced records in select/option drop-downs.
To set the
db.othertable.otherfield.representattribute for all fields referencing this table. This means that theFormconstructor will not show references by id but will use the preferred format representation instead.
`` Rname``: nome real
rname sets a database backend name for the table. This makes the
py4web table name an alias, and rname is the real name used when
constructing the query for the backend. To illustrate just one use,
rname can be used to provide MSSQL fully qualified table names
accessing tables belonging to other databases on the server:
rname = 'db1.dbo.table1'
`` Primarykey``: Suporte para tabelas legadas
primarykey helps support legacy tables with existing primary keys,
even multi-part. See Legacy databases and keyed tables.
`` Migrate``, `` fake_migrate``
migrate sets migration options for the table. Refer to
Migrations for details.
`` Table_class``
If you define your own table class as a sub-class of pydal.objects.Table, you can provide it here; this allows you to extend and override methods. Example:
from pydal.objects import Table
class MyTable(Table):
...
db.define_table(..., table_class=MyTable)
`` Sequence_name``
O nome de uma seqüência tabela personalizada (se suportado pelo banco de dados). Pode criar uma seqüência (a partir de 1 e incrementando por 1) ou usar isso para tabelas legadas com seqüências personalizadas.
Observe que, quando necessário, py4web vai criar seqüências automaticamente por padrão.
`` Trigger_name``
Refere-se a `` sequence_name``. Relevante para alguns backends que não suportam campos numéricos auto-incremento.
`` polymodel``
For use with Google App Engine.
`` On_define``
`` On_define`` é uma chamada de retorno acionado quando um lazy_table é instanciado, embora ela é chamada de qualquer maneira, se a tabela não é preguiçoso. Isso permite que mudanças dinâmicas para a mesa sem perder as vantagens de instanciação adiada.
Exemplo:
db = DAL(lazy_tables=True)
db.define_table('person',
Field('name'),
Field('age', 'integer'),
on_define=lambda table: [
table.name.set_attributes(requires=IS_NOT_EMPTY(), default=''),
table.age.set_attributes(requires=IS_INT_IN_RANGE(0, 120), default=30) ])
Nota Este exemplo mostra como usar `` on_define`` mas não é realmente necessário. O simples `` valores requires`` poderiam ser adicionados às definições de campo ea mesa ainda seria preguiçoso. No entanto, `` requires`` que tomar um objeto definido como o primeiro argumento, como IS_IN_DB, vai fazer uma consulta como `` db.sometable.somefield == some_value`` que causaria `` sometable`` a ser definido no início . Esta é a situação salvos por `` on_define``.
Adicionando atributos para campos e tabelas
Se você precisa adicionar atributos personalizados aos campos, você pode simplesmente fazer isso: `` db.table.field.extra = {} ``
“extra” is not a keyword; it’s a custom attribute now attached to the field object. You can do it with tables too but they must be preceded by an underscore to avoid naming conflicts with fields:
db.table._extra = {}
Bancos de dados legados e tabelas com chave
py4web pode se conectar a bancos de dados legados sob algumas condições.
The easiest way is when these conditions are met:
Each table must have a unique auto-increment integer field called “id”.
Records must be referenced exclusively using the “id” field.
Ao acessar uma tabela existente, isto é, uma tabela não criado por py4web no aplicativo atual, sempre definir `` migrar = False``.
If the legacy table has an auto-increment integer field but it is not
called “id”, py4web can still access it but the table definition must
declare the auto-increment field with ‘id’ type (that is using
Field('...', 'id')).
Finalmente se a tabela de legado usa uma chave primária que não é um campo id auto-incremento é possível usar uma “mesa com chave”, por exemplo:
db.define_table('account',
Field('accnum', 'integer'),
Field('acctype'),
Field('accdesc'),
primarykey=['accnum', 'acctype'],
migrate=False)
`` Primarykey`` é uma lista dos nomes de campo que compõem a chave primária.
Todos os campos PrimaryKey tem um `` NÃO NULL`` definido, mesmo se não especificado.
Tabelas com chave só podem referenciar outras tabelas com chave.
Campos de referência devem usar o
reference tablename.fieldname.A `` função update_record`` não está disponível para filas de mesas com chave.
Atualmente tabelas chaveadas são suportadas apenas para DB2, MSSQL, Ingres e Informix, mas serão adicionados outros engines.
No momento da escrita, não podemos garantir que os `` obras de atributos primarykey`` com cada mesa legado existente e cada backend de banco de dados suportado. Para simplificar, recomendamos, se possível, criando uma visão do banco de dados que tem um campo id auto-incremento.
Construtor Field
Estes são os valores padrão de um construtor de campo:
Field(fieldname, type='string', length=None, default=DEFAULT,
required=False, requires=DEFAULT,
ondelete='CASCADE', notnull=False, unique=False,
uploadfield=True, widget=None, label=None, comment=None,
writable=True, readable=True, searchable=True, listable=True,
update=None, authorize=None, autodelete=False, represent=None,
uploadfolder=None, uploadseparate=None, uploadfs=None,
compute=None, filter_in=None, filter_out=None,
custom_qualifier=None, map_none=None, rname=None)
onde padrão é um valor especial usado para permitir que o valor Nenhum para um parâmetro.
Nem todos eles são relevantes para todos os campos. `` Length`` é relevante apenas para campos do tipo “string”. `` Uploadfield``, `` authorize``, e `` autodelete`` são relevantes apenas para campos do tipo “Upload”. `` Ondelete`` é relevante apenas para campos do tipo “referência” e “Upload”.
`` Length`` define o comprimento máximo de uma “string”, “password” ou campo “Upload”. Se `` length`` não for especificado um valor padrão é usado, mas o valor padrão não é garantido para ser compatível. * Para evitar migrações indesejadas em upgrades, recomendamos que você sempre especificar o comprimento de campos de cordas, senha e upload. *
`` Default`` define o valor padrão para o campo. O valor padrão é utilizada quando se realiza uma inserção se um valor não for especificado explicitamente. É também usado para formas construídas a partir da tabela usando `` Form``-preencher previamente. Note, em vez de ser um valor fixo, o padrão em vez disso pode ser uma função (incluindo uma função lambda) que retorna um valor do tipo apropriado para o campo. Nesse case, a função é chamada uma vez para cada registro inserido, mesmo quando vários registros são inseridos em uma única transação.
`` Required`` conta a DAL que nenhuma inserção deve ser permitido nesta tabela se um valor para este campo não é especificado explicitamente.
requiresis a validator or a list of validators. This is not used by the DAL, but instead it is used byForm(this will be explained better on the Forumlários chapter). The default validators for the given types are shown in the next section Field types and validators.Nota
while
requires=...is enforced at the level of forms,required=Trueis enforced at the level of the DAL (insert). In addition,notnull,uniqueandondeleteare enforced at the level of the database. While they sometimes may seem redundant, it is important to maintain the distinction when programming with the DAL.`` Rname`` fornece o campo com um “nome real”, um nome para o campo conhecido para o adaptador de banco de dados; quando o campo é usado, ele é o valor rname que é enviado para o banco de dados. O nome py4web para o campo é então efetivamente um alias.
`` Ondelete`` traduz na “ON DELETE” instrução SQL. Por padrão, ele é definido como “em cascata”. Isso diz ao banco de dados que quando se exclui um registro, ele também deve excluir todos os registros que se referem a ele. Para desativar este recurso, conjunto de `` ondelete`` a “nenhuma acção” ou “NULL SET”.
`` Notnull = True`` se traduz na “NOT NULL” instrução SQL. Ela impede que a banco de dados a partir da inserção de valores nulos para o campo.
`` Unique = True`` se traduz na instrução SQL “único” e ele garante que os valores deste campo são exclusivos dentro da tabela. Ela é aplicada no nível de banco de dados.
uploadfieldapplies only to fields of type “upload”. A field of type “upload” stores the name of a file saved somewhere else, by default on the filesystem under the application “uploads/” folder. Ifuploadfieldis set to True, then the file is stored in a blob field within the same table and the value ofuploadfieldis the name of the blob field. This will be discussed in more detail later in More on uploads.uploadfoldermust be set to a location where to store uploaded files. The scaffolding app defines a foldersettings.UPLOAD_FOLDERwhich points toapps/{app_name}/uploadsso you can set, for example,Field(... uploadfolder=settings.UPLOAD_FOLDER).uploadseparateif set to True will upload files under different subfolders of the uploadfolder folder. This is optimized to avoid too many files under the same folder/subfolder. ATTENTION: You cannot change the value ofuploadseparatefrom True to False without breaking links to existing uploads. pydal either uses the separate subfolders or it does not. Changing the behavior after files have been uploaded will prevent pydal from being able to retrieve those files. If this happens it is possible to move files and fix the problem but this is not described here.`` Uploadfs`` permite que você especificar um sistema de arquivos diferente, onde fazer o upload de arquivos, incluindo um armazenamento Amazon S3 ou um armazenamento de SFTP remoto.
Você precisa ter PyFileSystem instalado para que isso funcione. `` Uploadfs`` deve apontar para PyFileSystem.
autodeletedetermines if the corresponding uploaded file should be deleted when the record referencing the file is deleted. For “upload” fields only. However, records deleted by the database itself due to a CASCADE operation will not trigger py4web’s autodelete.labelis a string (or a helper or something that can be serialized to a string that contains the label to be used for this field in auto-generated forms.) that contains a comment associated with this field, and will be displayed to the right of the input field in the autogenerated forms.`` Writable`` declara se um campo é gravável em formulários.
`` Readable`` declara se um campo é legível em formulários. Se um campo não é nem legível, nem gravável, não será exibido em criar e atualizar formas.
`` Update`` contém o valor padrão para este campo quando o registro é atualizado.
`` Compute`` é uma função opcional. Se um registro é inserido ou atualizado, a função de computação será executado eo campo será preenchido com o resultado da função. O registro é passado para a função de computação como um `` dict``, eo dict não incluirá o valor atual de que, ou qualquer outro campo de computação.
`` Authorize`` pode ser usado para exigir o controle de acesso no campo correspondente, para apenas os campos “Upload”. Ele será discutido mais em detalhe no contexto de autenticação e autorização.
widgetDo NOT use the widget parameter in py4web for a Field definition. (This was a feature of web2py and is not to be used in py4web) See Widgets later.representcan be None or can point to a function that takes a field value and returns an alternate representation for the field value.
Thread safety and Field attributes
Even though py4web and web2py use the same pyDAL, there is an important difference
which stems from the core architecture of py4web.
In py4web only the following Field attributes can be changed inside an action:
readablewritabledefaultfilter_infilter_outlabelupdaterequireswidgetrepresent
These are reset to their original values before each action is called.
All other Field, DAL, and Table attributes are global and non-thread-safe.
This limitation exists because py4web executes table definitions only at startup, unlike web2py which re-defines tables on each request. This makes py4web a lot faster than web2py, but you need to be careful as modifying non-thread-safe attributes in actions can cause race conditions and bugs.
Field types and validators
Type |
Default validators |
|---|---|
`` String`` |
`` IS_LENGTH (comprimento) `` comprimento padrão é 512 |
`` text`` |
`` IS_LENGTH (comprimento) `` comprimento padrão é 32.768 |
`` blob`` |
`` Comprimento padrão None`` é 2 ** 31 (2 GIB) |
`` boolean`` |
`` None`` |
`` integer`` |
`` IS_INT_IN_RANGE (** -2 31, 2 ** 31) `` |
`` Double`` |
`` IS_FLOAT_IN_RANGE (-1e100, 1e100) `` |
`` Decimal (n, m) `` |
|
`` date`` |
`` IS_DATE () `` |
`` Time`` |
`` IS_TIME () `` |
`` datetime`` |
`` IS_DATETIME () `` |
`` password`` |
`` IS_LENGTH (comprimento) `` comprimento padrão é 512 |
`` Upload`` |
`` Comprimento padrão é 512 None`` |
`` Referência <table> `` |
`` IS_IN_DB (db, table.field, formato) `` |
`` Lista: string`` |
`` None`` |
`` Lista: integer`` |
`` None`` |
`` Lista: referência <table> `` |
|
`` json`` |
`` IS_EMPTY_OR (IS_JSON ()) `` comprimento padrão é 512 |
`` bigint`` |
`` IS_INT_IN_RANGE (** -2 63, 2 ** 63) `` |
`` Grande-id`` |
`` None`` |
`` Grande-reference`` |
`` None`` |
Decimal requer e devolve valores como `` objectos Decimal``, como definidos na Python `` decimal`` módulo. SQLite não lidar com o `` decimal`` tipo assim internamente que tratá-lo como um `` double``. O (n, m) são o número de dígitos no total e o número de dígitos após o ponto decimal, respectivamente.
A `` grande-id`` e, `` grande-reference`` são suportados apenas por alguns dos mecanismos de bases de dados e são experimentais. Eles não são normalmente usados como tipos de campo a menos de tabelas legadas, no entanto, o construtor DAL tem um argumento `` bigint_id`` que, quando definido para `` True`` faz com que os `` campos id`` e `` campos reference`` `` grande-id`` e `` grande-reference`` respectivamente.
The list:<type> fields are special because they are designed to take
advantage of certain denormalization features on NoSQL (in the case of
Google App Engine NoSQL, the field types ListProperty and
StringListProperty) and back-port them all the other supported
relational databases. On relational databases lists are stored as a
text field. The items are separated by a | and each | in
string item is escaped as a ||. They are discussed in
`` Lista: <type> `` e `` contains``.
The json field type is pretty much explanatory. It can store any
JSON serializable object. It is designed to work specifically for
MongoDB and backported to the other database adapters for portability.
blob fields are also special. By default, binary data is encoded in
base64 before being stored into the actual database field, and it is
decoded when extracted. This has the negative effect of using 33% more
storage space than necessary in blob fields, but has the advantage of
making the communication independent of the back-end specific escaping
conventions.
modificação da tabela e campo em tempo de execução
A maioria dos atributos de campos e tabelas podem ser modificados depois que eles são definidos:
>>> db.define_table('person', Field('name', default=''), format='%(name)s')
<Table person (id, name)>
>>> db.person._format = '%(name)s/%(id)s'
>>> db.person.name.default = 'anonymous'
aviso de que os atributos de tabelas são geralmente precedido por um sublinhado para evitar conflitos com possíveis nomes de campo.
Você pode listar as tabelas que foram definidos para uma determinada conexão com o banco:
>>> db.tables
['person']
Você pode consultar para o tipo de uma tabela:
>>> type(db.person)
<class 'pydal.objects.Table'>
Você pode acessar uma tabela utilizando diferentes sintaxes:
>>> db.person is db['person']
True
Você também pode listar os campos que foram definidos para uma determinada tabela:
>>> db.person.fields
['id', 'name']
Da mesma forma você pode acessar campos de seu nome de várias maneiras equivalentes:
>>> type(db.person.name)
<class 'pydal.objects.Field'>
>>> db.person.name is db.person['name']
True
Dado um campo, você pode acessar os atributos definidos em sua definição:
>>> db.person.name.type
string
>>> db.person.name.unique
False
>>> db.person.name.notnull
False
>>> db.person.name.length
32
incluindo a sua tabela pai, tablename, e ligação parent:
>>> db.person.name._table == db.person
True
>>> db.person.name._tablename == 'person'
True
>>> db.person.name._db == db
True
Um campo também tem métodos. Alguns deles são utilizados para consultas de construção e vamos vê-los mais tarde. Um método especial do objeto de campo é `` validate`` e chama os validadores para o campo.
>>> db.person.name.validate('John')
('John', None)
que retorna um tuplo `` (valor, erro) . `` `` Error é None`` se a entrada passa a validação.
Mais sobre envios
Considere o seguinte modelo:
db.define_table('myfile',
Field('image', 'upload', default='path/to/file'))
No case de um campo de “carregamento”, o valor padrão pode, opcionalmente, ser definida como um caminho (um caminho absoluto ou um caminho relativo para a pasta aplicativo atual), o valor padrão é então atribuído a cada novo registro que não especifica um imagem.
Observe que desta forma vários registros podem acabar com referência ao mesmo arquivo de imagem padrão e isso poderia ser um problema em um campo ter `` autodelete`` habilitado. Quando você não quer permitir duplicatas para o campo de imagem (ou seja, vários registros referenciando o mesmo arquivo), mas ainda quer definir um valor padrão para o “carregamento”, então você precisa de uma forma de copiar o arquivo padrão para cada novo registro que faz não especificar uma imagem. Isto pode ser obtido usando um arquivo-como objeto referenciando o arquivo padrão como o argumento `` default`` ao campo, ou mesmo com:
Field('image', 'upload', default=dict(data='<file_content>', filename='<file_name>'))
Normalmente uma inserção é feita automaticamente através de um `` Form`` mas ocasionalmente você já tem o arquivo no sistema de arquivos e quer enviá-lo por meio de programação. Isso pode ser feito da seguinte maneira:
with open(filename, 'rb') as stream:
db.myfile.insert(image=db.myfile.image.store(stream, filename))
Também é possível inserir um arquivo de uma forma mais simples e tem a chamada de método de inserção `` store`` automaticamente:
with open(filename, 'rb') as stream:
db.myfile.insert(image=stream)
Neste case, o nome do ficheiro é obtido a partir do objecto corrente, se disponível.
O método store` do objeto campo carregamento leva um fluxo de arquivo e um nome de arquivo. Ele usa o nome do arquivo para determinar a extensão (tipo) do arquivo, cria um novo nome temporário para o arquivo (de acordo com mecanismo de upload py4web) e carrega o conteúdo do arquivo neste novo arquivo temporário (sob os envios de pasta salvo indicação em contrário). Ele retorna o novo nome temp, que é então armazenada no campo `` image`` da tabela `` db.myfile``.
Note, se o arquivo deve ser armazenado em um campo blob associado ao invés do sistema de arquivos, o método store` não irá inserir o arquivo no campo blob (porque` store` é chamado antes da inserção), portanto, o arquivo deve ser explicitamente inserido no campo blob:
db.define_table('myfile',
Field('image', 'upload', uploadfield='image_file'),
Field('image_file', 'blob'))
with open(filename, 'rb') as stream:
db.myfile.insert(image=db.myfile.image.store(stream, filename),
image_file=stream.read())
O método retrieve` faz o oposto do` store`.
Quando os arquivos enviados são armazenados no sistema de arquivos (como no case de um `` Field ( “imagem” simples, “upload”) ``) o código:
row = db(db.myfile).select().first()
(filename, fullname) = db.myfile.image.retrieve(row.image, nameonly=True)
recupera o nome do arquivo original (filename) como visto pelo usuário em tempo de upload e o nome do arquivo armazenado (fullname, com caminho relativo para a pasta da aplicação). Embora, em geral, a chamada:
(filename, stream) = db.myfile.image.retrieve(row.image)
recupera o nome original do arquivo (filename) e um arquivo-como objeto pronto para dados de arquivo de acesso carregado (stream).
Observe que o fluxo retornado por `` retrieve`` é um objeto de arquivo real no case de que os arquivos enviados são armazenados no sistema de arquivos. Nesse case, lembre-se de fechar o arquivo quando você é feito, chamando `` stream.close () ``.
Aqui está um exemplo de uso seguro do `` retrieve``:
from contextlib import closing
import shutil
row = db(db.myfile).select().first()
(filename, stream) = db.myfile.image.retrieve(row.image)
with closing(stream) as src, closing(open(filename, 'wb')) as dest:
shutil.copyfileobj(src, dest)
Migrações
With our example table definition:
db.define_table('person')
define_table checks whether or not the corresponding table exists.
If it does not, it generates the SQL to create it and executes the SQL.
If the table does exist but differs from the one being defined, it
generates the SQL to alter the table and executes it. If a field has
changed type but not name, it will try to convert the data (If you do
not want this, you need to redefine the table twice, the first time,
letting py4web drop the field by removing it, and the second time adding
the newly defined field so that py4web can create it). If the table
exists and matches the current definition, it will leave it alone. In
all cases it will create the db.person object that represents the
table.
Referimo-nos a esse comportamento como uma “migração”. py4web registra todas as migrações e migração tentativas no arquivo “Sql.log”.
Nota
by default py4web uses the “app/databases” folder for the
log file and all other migration files it needs. You can change this
setting by changing the folder argument to DAL. To set a different
log file name, for example “migrate.log” you can do
db = DAL(..., adapter_args=dict(logfile='migrate.log'))
The first argument of define_table is always the table name. The
other unnamed arguments are the fields. The function also takes
an optional keyword argument called “migrate”:
db.define_table('person', ..., migrate='person.table')
O valor de migrar é o nome do arquivo onde as informações lojas py4web migração interna para esta tabela. Esses arquivos são muito importantes e nunca deve ser removido enquanto existirem as tabelas correspondentes. Nos cases em que uma tabela foi descartado eo arquivo correspondente ainda existem, ele pode ser removido manualmente. Por padrão, migre é definida como True. Este causas py4web para gerar o nome do arquivo a partir de um hash da string de conexão. Se migre é definida como falso, a migração não é realizada, e py4web assume que a tabela existe no armazenamento de dados e que contém (pelo menos) os campos listados no `` define_table``.
Não pode haver duas tabelas no mesmo aplicativo com o mesmo nome migrar.
A classe DAL também leva um argumento “migrar”, que determina o valor padrão de migrar para chamadas para `` define_table``. Por exemplo,
db = DAL('sqlite://storage.sqlite', migrate=False)
irá definir o valor padrão de migrar para Falso quando `` db.define_table`` é chamado sem um argumento migrar.
Nota
py4web only migrates new columns, removed columns, and
changes in column type (except in SQLite). py4web does not migrate
changes in attributes such as changes in the values of default,
unique, notnull, and ondelete.
As migrações podem ser desativado para todas as tabelas de uma só vez:
db = DAL(..., migrate_enabled=False)
This is the recommended behavior when two apps share the same database. Only one of the two apps should perform migrations, the other should disable them.
Fixação migrações quebrados
Há dois problemas comuns com as migrações e existem formas de recuperar a partir deles.
Um problema é específico com SQLite. SQLite não impor tipos de coluna e não pode soltar colunas. Isto significa que se você tiver uma coluna do tipo string e você removê-lo, não é realmente removido. Se você adicionar a coluna novamente com um tipo diferente (por exemplo, data e hora) você acaba com uma coluna de data e hora que contém strings (lixo para fins práticos). não py4web não reclamar sobre isso, porque ele não sabe o que está no banco de dados, até que ele tenta recuperar registros e falha.
Se py4web retorna um erro em alguma função de análise ao selecionar registros, muito provavelmente isso é devido a dados corrompidos em uma coluna por causa da questão acima.
A solução consiste em actualizar todos os registos da tabela e a actualização dos valores na coluna em questão com Nenhum.
O outro problema é mais genérico, mas típico com MySQL. O MySQL não permitem mais de um ALTER TABLE em uma transação. Isto significa que py4web deve quebrar transações complexas em partes menores (um ALTER TABLE na época) e cometem uma peça no momento. Por isso, é possível que parte de uma transação complexa fica comprometida e uma parte falhar, deixando py4web em um estado corrompido. Por que parte de uma transação falhar? Uma vez que, por exemplo, envolve a alteração de uma tabela de conversão e uma coluna de strings dentro de uma coluna de data e hora, tentativas py4web para converter os dados, mas os dados não podem ser convertidos. O que acontece com py4web? Ele fica confuso sobre o que exatamente é a estrutura da tabela realmente armazenados no banco de dados.
A solução consiste em permitir migrações falsos:
db.define_table(...., migrate=True, fake_migrate=True)
Isto irá reconstruir metadados py4web sobre a tabela de acordo com a definição da tabela. Tente várias definições de tabela para ver qual delas funciona (aquele antes da migração falhou ea uma após a migração falhou). Uma vez que remove sucesso do `` fake_migrate = True`` parâmetro.
Before attempting to fix migration problems it is prudent to make a copy of “yourapp/databases/*.table” files.
Migração problemas também pode ser fixada para todas as tabelas de uma só vez:
db = DAL(..., fake_migrate_all=True)
Isso também falhará se o modelo descreve tabelas que não existem no banco de dados, mas pode ajudar a estreitar o problema.
Migração resumo controle
A lógica dos vários argumentos de migração estão resumidos neste pseudo-código:
if DAL.migrate_enabled and table.migrate:
if DAL.fake_migrate_all or table.fake_migrate:
perform fake migration
else:
perform migration
Table methods
`` Insert``
Dada uma tabela, você pode inserir registros
>>> db.person.insert(name="Alex")
1
>>> db.person.insert(name="Bob")
2
Inserir retorna o valor único “id” de cada registro inserido.
Você pode truncar a tabela, ou seja, excluir todos os registros e reinicie o contador do id.
>>> db.person.truncate()
Agora, se você inserir um registro novo, o contador recomeça a 1 (isto é específico back-end e não se aplica ao Google NoSQL):
>>> db.person.insert(name="Alex")
1
Observe que você pode passar um parâmetro para `` truncate``, por exemplo, você pode dizer SQLite para reiniciar o contador id.
>>> db.person.truncate('RESTART IDENTITY CASCADE')
O argumento é em SQL puro e, portanto, específico do motor.
py4web também fornece um método bulk_insert
>>> db.person.bulk_insert([{'name': 'Alex'}, {'name': 'John'}, {'name': 'Tim'}])
[3, 4, 5]
É preciso uma lista de dicionários de campos a serem inseridas e executa várias inserções ao mesmo tempo. Ele retorna a lista de valores “id” dos registros inseridos. Nos bancos de dados relacionais suportadas não há nenhuma vantagem em usar esta função ao invés de looping e realizando inserções individuais, mas no Google App Engine NoSQL, há uma grande vantagem de velocidade.
`` Query``, `` Set``, `` Rows``
Vamos considerar novamente a tabela definida (e caiu) anteriormente e inserir três registros:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> db.person.insert(name="Alex")
1
>>> db.person.insert(name="Bob")
2
>>> db.person.insert(name="Carl")
3
Você pode armazenar a tabela em uma variável. Por exemplo, com variável `` Person``, você poderia fazer:
>>> person = db.person
Você também pode armazenar um campo em uma variável como `` name``. Por exemplo, você também pode fazer:
>>> name = person.name
Você pode até criar uma consulta (usando operadores como ==, =, <,>, <=,> =, como, pertence!) E armazenar a consulta em uma variável `` q`` tal como em:
>>> q = name == 'Alex'
Quando você chamar `` db`` com uma consulta, você define um conjunto de registros. Você pode armazená-lo em uma variável `` s`` e escreve:
>>> s = db(q)
Observe que nenhuma consulta de banco de dados foi realizada até agora. DAL + consulta simplesmente definir um conjunto de registros neste db que correspondem a consulta. py4web determina a partir da consulta que tabela (ou tabelas) estão envolvidos e, de fato, não há necessidade de especificar isso.
`` Update_or_insert``
Algumas vezes você precisa executar uma inserção somente se não há nenhum registro com os mesmos valores como aqueles que estão sendo inseridos. Isso pode ser feito com
db.define_table('person',
Field('name'),
Field('birthplace'))
db.person.update_or_insert(name='John', birthplace='Chicago')
O registro será inserido somente se não houver nenhum outro usuário chamado John nascido em Chicago.
Você pode especificar quais valores usar como uma chave para determinar se existe o registro. Por exemplo:
db.person.update_or_insert(db.person.name == 'John',
name='John',
birthplace='Chicago')
e se houver John sua terra natal será atualizado então um novo registro será criado.
Os critérios de selecção no exemplo acima é um único campo. Ele também pode ser uma consulta, tais como
db.person.update_or_insert((db.person.name == 'John') & (db.person.birthplace == 'Chicago'),
name='John',
birthplace='Chicago',
pet='Rover')
`` Validate_and_insert``, `` validate_and_update``
A função
ret = db.mytable.validate_and_insert(field='value')
funciona muito bem como
id = db.mytable.insert(field='value')
except that it calls the validators for the fields before performing the
insert and bails out if the validation does not pass. If validation does
not pass the errors can be found in ret["errors"]. ret["errors"] holds
a key-value mapping where each key is the field name whose validation
failed, and the value of the key is the result from the validation error
(much like form["errors"]). If it passes, the id of the new record is
in ret["id"]. Mind that normally validation is done by the form
processing logic so this function is rarely needed.
Similarmente
ret = db(query).validate_and_update(field='value')
funciona muito da mesma forma como
num = db(query).update(field='value')
except that it calls the validators for the fields before performing the
update. Notice that it only works if query involves a single table. The
number of updated records can be found in ret["updated"] and errors
will be in ret["errors"].
`` Drop``
Finalmente, você pode soltar tabelas e todos os dados serão perdidos:
db.person.drop()
QueryBuilder
You can generate DAL queries using natural language. This can be done as follows:
from py4web import DAL, Field
from pydal import QueryBuilder, QueryParseError
db = DAL("sqlite:memory")
db.define_table("thing", Field("name"), Field("solid", "boolean"))
builder = QueryBuilder(db.thing)
query = builder.parse('name is equal to Chair')
rows = db(query).select()
Example of valid expressions are:
name is null
name is not null
name == Chair
name is Chair
name is equal Chair
name is equal to Chair
name is equal to «Chair»
name lower is equal to Chair
not name lower is equal to Chair
not (name lower is equal to Chair)
name == Chair or name == Table
name starts with C and name contains air
name in Chair, Table, Glass
name belongs Chair, Table, «Glass Top»
solid is true
solid is false
Notice that quotes are optional and only for values. You can use brakets to group. It throws a QueryParseError exception on failure. You can pass optional parameters to QueryBuilder for internationalization purposes (Italian in example):
builder = QueryBuilder(db.thing,
field_aliases={"id": "id", "nome": "name"},
token_aliases={"non è nullo": "is not null", "è uguale a": "=="})
query = builder.parse('nome non è nullo')
query = builder.parse('nome è uguale a Tavolo')
If field_aliases is not provided, only readable fields can be searched. If field_aliases is provided, only explicitedly included field names can be searched.
You can, of course, use the translation operator T:
builder = QueryBuilder(db.thing,
field_aliases={str(T(field.name)): field name for field in db.thing},
token_aliases={str(T(key):key) for key in QueryBuilder.token_ops})
You can alias the following tokens:
{
# boolean tokens
"not",
"and",
"or",
# field transformers
"upper",
"lower",
# unary search expressions
"is null",
"is not null",
"is true",
"is false",
# binary search expressions
"==",
"!=",
"<",
">",
"<=",
">=",
"contains",
"startswith", # notice "starts with" is an alias!
# search in list
"belongs",
}
The query builder is used in the Grid. In the Grid the field aliases are the field.label in lower case with the spaces replaced by underscore.
Marcação de registros
Etiquetas permite adicionar ou encontrar propriedades anexadas aos registros em seu banco de dados.
from py4web import DAL, Field
from pydal.tools.tags import Tags
db = DAL("sqlite:memory")
db.define_table("thing", Field("name"))
id1 = db.thing.insert(name="chair")
id2 = db.thing.insert(name="table")
properties = Tags(db.thing)
properties.add(id1, "color/red")
properties.add(id1, "style/modern")
properties.add(id2, "color/green")
properties.add(id2, "material/wood")
assert properties.get(id1) == ["color/red", "style/modern"]
assert properties.get(id2) == ["color/green", "material/wood"]
rows = db(properties.find(["style/modern"])).select()
assert rows.first().id == id1
rows = db(properties.find(["material/wood"])).select()
assert rows.first().id == id2
rows = db(properties.find(["color"])).select()
assert len(rows) == 2
Tags are hierarchical. Then find([“color”]) would return id1 and id2
because both records have tags with “color”.
It is internally implemented with the creation of an additional table, which in
this example would be db.thing_tags_default, because no tail was
specified on the Tags(table, tail=“default”) constructor.
py4web uses Tags as a flexible mechanism to manage permissions, we’ll see
all the details later on the Authorization using Tags chapter.
Raw SQL
`` executesql``
A DAL permite emitir explicitamente instruções SQL.
>>> db.executesql('SELECT * FROM person;')
[(1, u'Massimo'), (2, u'Massimo')]
Neste case, os valores de retorno não são analisados ou transformados pela DAL, eo formato depende do driver de banco de dados específico. Este uso com selecciona normalmente não é necessário, mas é mais comum com índices.
`` Executesql`` leva cinco argumentos opcionais: `` placeholders``, `` as_dict``, `` fields``, `` colnames``, e `` as_ordered_dict``.
`` Placeholders`` é uma seqüência opcional de valores a serem substituídos ou, se suportado pelo driver DB, um dicionário com chaves correspondentes chamado espaços reservados no seu SQL.
If as_dict is set to True, the results cursor returned by the DB
driver will be converted to a sequence of dictionaries keyed with the db
field names. Results returned with as_dict = True are the same as
those returned when applying as_list() to a normal select:
[{'field1': val1_row1, 'field2': val2_row1}, {'field1': val1_row2, 'field2': val2_row2}]
`` As_ordered_dict`` é muito bonito como `` as_dict`` mas os antigos garante que a ordem dos resultando campos (teclas OrderedDict) refletem a ordem em que eles são retornados de DB motorista:
[OrderedDict([('field1', val1_row1), ('field2', val2_row1)]),
OrderedDict([('field1', val1_row2), ('field2', val2_row2)])]
O argumento `` fields`` é uma lista de objetos DAL de campo que correspondem aos campos retornados da DB. Os objectos de campo devem ser parte de um ou mais objectos Tabela definido no objecto DAL. A `` lista fields`` pode incluir um ou mais DAL Tabela objetos em adição a ou em vez de incluir Campo objetos, ou pode ser apenas uma única tabela (não de uma lista). Nesse case, os objectos de campo vai ser extraído da tabela (s).
Em vez de especificar o argumento `` fields``, o argumento `` colnames`` pode ser especificado como uma lista de nomes de campos em formato tabela.campo. Novamente, estes devem representar tabelas e campos definidos no objeto DAL.
Também é possível especificar `` fields`` eo associado `` colnames``. Nesse case, `` fields`` pode também incluir objetos Expressão DAL, além de objetos de campo. Para objetos de campo em “campos”, o associado `` colnames`` ainda deve estar no formato tabela.campo. Para Expression objetos em `` fields``, o associado `` colnames`` podem ser quaisquer rótulos arbitrários.
Observe, a Tabela DAL objectos referidos por `` fields`` ou `` colnames`` pode ser fictícios mesas e não têm para representar todas as tabelas reais no banco de dados. Além disso, nota que o `` fields`` e `` colnames`` devem estar na mesma ordem que os campos nos resultados cursor retornado do DB.
`` _Lastsql``
Se SQL foi executado manualmente usando ExecuteSQL ou foi SQL gerado pelo DAL, você sempre pode encontrar o código SQL em `` db._lastsql``. Isso é útil para fins de depuração:
>>> rows = db().select(db.person.ALL)
>>> db._lastsql
SELECT person.id, person.name FROM person;
py4web never generates queries using the “*” operator. py4web is always explicit when selecting fields.
Temporização de consultas
All queries are automatically timed by py4web. The variable
db._timings is a list of tuples. Each tuple contains the raw SQL
query as passed to the database driver and the time it took to execute
in seconds.
Índices
Atualmente, a API DAL não fornece um comando para criar índices em tabelas, mas isso pode ser feito usando o comando `` executesql``. Isso ocorre porque a existência de índices pode fazer migrações complexa, e é melhor para lidar com eles de forma explícita. Os índices podem ser necessários para esses campos que são usados em consultas recorrentes.
Aqui está um exemplo de como:
db = DAL('sqlite://storage.sqlite')
db.define_table('person', Field('name'))
db.executesql('CREATE INDEX IF NOT EXISTS myidx ON person (name);')
Outros dialetos banco de dados têm sintaxes muito semelhantes, mas pode não suportar o opcional “SE NÃO EXISTE” directiva.
Generating raw SQL
Às vezes você precisa para gerar o SQL, mas não executá-lo. Isso é fácil de fazer com py4web uma vez que cada comando que executa banco de dados IO tem um comando equivalente que não, e simplesmente retorna o SQL que teriam sido executados. Estes comandos têm os mesmos nomes e sintaxe como os funcionais, mas eles começam com um sublinhado:
Aqui é `` _insert``
>>> print(db.person._insert(name='Alex'))
INSERT INTO "person"("name") VALUES ('Alex');
Aqui é `` _count``
>>> print(db(db.person.name == 'Alex')._count())
SELECT COUNT(*) FROM "person" WHERE ("person"."name" = 'Alex');
Aqui é `` _select``
>>> print(db(db.person.name == 'Alex')._select())
SELECT "person"."id", "person"."name" FROM "person" WHERE ("person"."name" = 'Alex');
Aqui é `` _delete``
>>> print(db(db.person.name == 'Alex')._delete())
DELETE FROM "person" WHERE ("person"."name" = 'Alex');
E, finalmente, aqui é `` _update``
>>> print(db(db.person.name == 'Alex')._update(name='Susan'))
UPDATE "person" SET "name"='Susan' WHERE ("person"."name" = 'Alex');
Além disso, você sempre pode usar `` db._lastsql`` para retornar o código SQL mais recente, se foi executada manualmente usando ExecuteSQL ou foi SQL gerado pelo DAL.
`` Comando SELECT``
Dado um conjunto, `` s``, você pode buscar os registros com o comando `` SELECT``:
>>> rows = s.select()
It returns an iterable object of class pydal.objects.Rows whose
elements are Row objects. pydal.objects.Row objects act like
dictionaries, but their elements can also be accessed as attributes.
The former differ from the latter because
its values are read-only.
O objecto Fileiras permite loop sobre o resultado do seleccionar e imprimindo os valores dos campos seleccionados para cada linha:
>>> for row in rows:
... print(row.id, row.name)
...
1 Alex
Você pode fazer todas as etapas em uma declaração:
>>> for row in db(db.person.name == 'Alex').select():
... print(row.name)
...
Alex
O comando select pode tomar argumentos. Todos os argumentos sem nome são interpretados como os nomes dos campos que você deseja buscar. Por exemplo, você pode ser explícita no campo “id” e no campo “nome” buscar:
>>> for row in db().select(db.person.id, db.person.name):
... print(row.name)
...
Alex
Bob
Carl
O atributo mesa ALL permite especificar todos os campos:
>>> for row in db().select(db.person.ALL):
... print(row.id, row.name)
...
1 Alex
2 Bob
3 Carl
Observe que não há nenhuma strings de consulta passada para db. py4web entende que se você quiser todos os campos da pessoa mesa sem informações adicionais, então você quer todos os registros da pessoa mesa.
Uma sintaxe alternativa equivalente é o seguinte:
>>> for row in db(db.person).select():
... print(row.id, row.name)
...
1 Alex
2 Bob
3 Carl
e py4web entende que se você perguntar para todos os registros da pessoa mesa sem informações adicionais, então você quer todos os campos da tabela pessoa.
Dada uma linha
>>> row = rows[0]
você pode extrair seus valores usando várias expressões equivalentes:
>>> row.name
Alex
>>> row['name']
Alex
>>> row('person.name')
Alex
The latter syntax is particularly handy when selecting an expression instead of a column. We will show this later.
Você também pode fazer
rows.compact = False
desativar a notação
rows[i].name
e permitir que, em vez disso, a notação menos compacto:
rows[i].person.name
Sim isso é incomum e raramente necessário.
Row objetos também tem dois métodos importantes:
row.delete_record()
e
row.update_record(name="new value")
Usando um seleto para uso de memória inferior à base de iterador
Python “iterators” são um tipo de “preguiçoso-avaliação”. Eles dados ‘alimentar’ um passo de tempo; laços tradicionais Python criar todo o conjunto de dados na memória antes de looping.
O uso tradicional de selecionar é:
for row in db(db.table).select():
...
mas para um grande número de linhas, usando uma alternativa à base de iterador tem uso de memória dramaticamente inferior:
for row in db(db.table).iterselect():
...
Testes mostram que isto é de cerca de 10% mais rápido, mesmo em máquinas com muita RAM.
Renderizando Rows com represent
Você pode querer reescrever linhas retornadas por seleção para tirar proveito de informações de formatação contida na representa a criação dos campos.
rows = db(query).select()
repr_row = rows.render(0)
Se você não especificar um índice, você tem um gerador para iterar sobre todas as linhas:
for row in rows.render():
print(row.myfield)
Também pode ser aplicada a fatias:
for row in rows[0:10].render():
print(row.myfield)
Se você só quer transformar campos selecionados através do seu atributo “representar”, você pode incluí-los no argumento “campos”:
repr_row = row.render(0, fields=[db.mytable.myfield])
Note, it returns a transformed copy of the original Row, so there’s no update_record (which you wouldn’t want anyway) or delete_record.
Atalhos
A DAL suporta vários atalhos-simplificando código. Em particular:
myrecord = db.mytable[id]
retorna o registro com o dado `` id`` se ele existir. Se o `` id`` não existe, ele retorna `` None``. A declaração acima é equivalente a
myrecord = db(db.mytable.id == id).select().first()
Você pode excluir registros por id:
del db.mytable[id]
e isto é equivalente a
db(db.mytable.id == id).delete()
e exclui o registro com o dado `` id``, se ele existir.
Nota: esta sintaxe de atalho de exclusão actualmente não trabalha se * versionamento * é ativado
Você pode inserir registros:
db.mytable[None] = dict(myfield='somevalue')
É equivalente a
db.mytable.insert(myfield='somevalue')
e cria um novo registro com valores de campos especificados pelo dicionário sobre o lado direito.
Note: insert shortcut was previously db.table[0] = .... It has
changed in pyDAL 19.02 to permit normal usage of id 0.
Você pode atualizar os registros:
db.mytable[id] = dict(myfield='somevalue')
o qual é equivalente a
db(db.mytable.id == id).update(myfield='somevalue')
e atualiza um registro existente com os valores dos campos especificados pelo dicionário sobre o lado direito.
A obtenção de um `` row``
No entanto, outra sintaxe conveniente é o seguinte:
record = db.mytable(id)
record = db.mytable(db.mytable.id == id)
record = db.mytable(id, myfield='somevalue')
Aparentemente semelhante a `` db.mytable [id] `` a sintaxe acima é mais flexível e mais seguro. Antes de tudo, verifica se `` id`` é um int (ou `` str (id) `` é um int) e retorna `` None`` se não (nunca levanta uma exceção). Ele também permite especificar várias condições que o registro deve atender. Se eles não forem atendidas, ele também retorna `` None``.
Recursivas `` s SELECT``
Considere a pessoa tabela anterior e uma nova tabela “coisa” fazendo referência a uma “pessoa”:
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
e um simples selecionar a partir desta tabela:
things = db(db.thing).select()
o qual é equivalente a
things = db(db.thing._id != None).select()
onde `` _id`` é uma referência para a chave principal da tabela. Normalmente `` db.thing._id`` é o mesmo que `` db.thing.id`` e vamos supor que na maior parte deste livro.
Para cada linha de coisas é possível buscar não apenas campos da tabela selecionada (coisa), mas também a partir de tabelas vinculadas (de forma recursiva):
for thing in things:
print(thing.name, thing.owner_id.name)
Aqui `` thing.owner_id.name`` requer um banco de dados escolha para cada coisa em coisas e por isso é ineficiente. Sugerimos usando junta sempre que possível, em vez de seleciona recursiva, no entanto, este é conveniente e prático ao acessar registros individuais.
Você também pode fazê-lo para trás, escolhendo os coisas referenciados por uma pessoa:
person = db.person(id)
for thing in person.thing.select(orderby=db.thing.name):
print(person.name, 'owns', thing.name)
Nesta última expressão `` person.thing`` é um atalho para
db(db.thing.owner_id == person.id)
isto é, o conjunto de thing`` `` s referenciados pelos actuais `` Person``. Esta sintaxe se decompõe se a tabela referenciando tem várias referências à tabela referenciada. Neste case é preciso ser mais explícito e usar uma consulta completa.
`` Orderby``, `` groupby``, `` limitby``, `` distinct``, `` having``, `` orderby_on_limitby``, `` join``, `` left``, `` cache``
O comando `` SELECT`` leva uma série de argumentos opcionais.
ordenar por
Você pode buscar os registros classificados pelo nome:
>>> for row in db().select(db.person.ALL, orderby=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
Você pode buscar os registros classificados pelo nome em ordem inversa (aviso o til):
>>> for row in db().select(db.person.ALL, orderby=~db.person.name):
... print(row.name)
...
Carl
Bob
Alex
Você pode ter os registros obtida aparecem em ordem aleatória:
>>> for row in db().select(db.person.ALL, orderby='<random>'):
... print(row.name)
...
Carl
Alex
Bob
O uso de `` orderby = “<random>” `` não é suportada no Google NoSQL. No entanto, para superar esse limite, a classificação pode ser feito em linhas selecionadas:
import random
rows = db(...).select().sort(lambda row: random.random())
Você pode classificar os registros de acordo com vários campos concatenando-los com um “|”:
>>> for row in db().select(db.person.name, orderby=db.person.name|db.person.id):
... print(row.name)
...
Alex
Bob
Carl
groupby, tendo
Usando `` groupby`` juntamente com `` orderby``, você pode agrupar registros com o mesmo valor para o campo especificado (isto é back-end específico, e não é sobre o Google NoSQL):
>>> for row in db().select(db.person.ALL,
... orderby=db.person.name,
... groupby=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
Pode usar `` having`` em conjunto com `` groupby`` ao grupo condicionalmente (apenas aqueles `` having`` a condição estão agrupados).
db(query1).select(db.person.ALL, groupby=db.person.name, having=query2)
Observe que os registros filtros Consulta1 a ser exibido, registros filtros Query2 ser agrupados.
distinto
Com o argumento `` distinta = True``, você pode especificar que você só quer selecionar registros distintos. Isto tem o mesmo efeito que o agrupamento usando todos os campos especificados, exceto que ele não necessita de classificação. Ao usar distinta é importante não para selecionar todos os campos, e em particular para não selecionar o campo “id”, senão todos os registros serão sempre distintas.
Aqui está um exemplo:
>>> for row in db().select(db.person.name, distinct=True):
... print(row.name)
...
Alex
Bob
Carl
Note que `` distinct`` também pode ser uma expressão, por exemplo:
>>> for row in db().select(db.person.name, distinct=db.person.name):
... print(row.name)
...
Alex
Bob
Carl
limitby
Com `` limitby = (min, max) ``, pode seleccionar um subconjunto dos registos de deslocamento = min, mas não incluindo offset = máx. No próximo exemplo nós selecionamos os dois primeiros registros a partir de zero:
>>> for row in db().select(db.person.ALL, limitby=(0, 2)):
... print(row.name)
...
Alex
Bob
orderby_on_limitby
Note-se que os padrões DAL de adicionar implicitamente um orderby ao usar um limitby. Isso garante a mesma consulta retorna os mesmos resultados de cada vez, importante para a paginação. Mas pode causar problemas de desempenho. use `` orderby_on_limitby = False`` para mudar isso (isso o padrão é True).
juntar-se, deixou
These are involved in managing One to many relation. They are described in Inner join and Left outer join sections respectively.
cache, em cache
An example use which gives much faster selects is:
rows = db(query).select(cache=(cache.get, 3600), cacheable=True)
Look at Caching selects, to understand what the trade-offs are.
Operadores lógicos
As consultas podem ser combinados usando o binário operador AND “` & `”:
>>> rows = db((db.person.name=='Alex') & (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
>>> len(rows)
0
eo binário operador OR “` | `”:
>>> rows = db((db.person.name == 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
1 Alex
Você pode negar uma sub-consulta invertendo o seu operador:
>>> rows = db((db.person.name != 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
2 Bob
3 Carl
ou pela negação explícita com o “` ~ `” operador unário:
>>> rows = db(~(db.person.name == 'Alex') | (db.person.id > 3)).select()
>>> for row in rows: print row.id, row.name
2 Bob
3 Carl
Devido a restrições de Python em sobrecarga “` and`” e “` or`” operadores, estes não podem ser utilizados na formação de consultas. Os operadores binários “` & ” e “ | ” deve ser usado em seu lugar. Note-se que estes operadores (ao contrário de “ and`” e “` or`”) tem precedência maior do que os operadores de comparação, de modo que os parênteses “extra” nos exemplos acima são de preenchimento obrigatório. Da mesma forma, o operador unitário “~` `` ” tem precedência mais elevada do que os operadores de comparação, de modo ~ ` `` comparações -negated também deve estar entre parênteses.
Também é possível consultas construir usando in-place operadores lógicos:
>>> query = db.person.name != 'Alex'
>>> query &= db.person.id > 3
>>> query |= db.person.name == 'John'
`` Count``, `` isempty``, `` DELETE``, `` update``
Você pode contar registros em um conjunto:
>>> db(db.person.name != 'William').count()
3
Note que `` count`` leva um opcional `` distinct`` argumento que o padrão é falso, e ele funciona muito parecido com o mesmo argumento para `` SELECT``. `` Count`` tem também um argumento `` cache`` que funciona muito parecido com o argumento equivalente do método SELECT`.
Às vezes você pode precisar verificar se uma tabela está vazia. Uma maneira mais eficiente do que a contagem está a utilizar o método isempty`:
>>> db(db.person).isempty()
False
Você pode excluir registros em um jogo:
>>> db(db.person.id > 3).delete()
0
A `` DELETE`` método devolve o número de registos que foram eliminados.
E você pode atualizar todos os registros em um conjunto, passando argumentos nomeados correspondentes aos campos que precisam ser atualizados:
>>> db(db.person.id > 2).update(name='Ken')
1
O método update` retorna o número de registros que foram atualizados.
Expressões
O valor atribuído uma instrução de atualização pode ser uma expressão. Por exemplo, considere este modelo
db.define_table('person',
Field('name'),
Field('visits', 'integer', default=0))
db(db.person.name == 'Massimo').update(visits = db.person.visits + 1)
Os valores usados em consultas também podem ser expressões
db.define_table('person',
Field('name'),
Field('visits', 'integer', default=0),
Field('clicks', 'integer', default=0))
db(db.person.visits == db.person.clicks + 1).delete()
`` case``
Uma expressão pode conter uma cláusula case, por exemplo:
>>> condition = db.person.name.startswith('B')
>>> yes_or_no = condition.case('Yes', 'No')
>>> for row in db().select(db.person.name, yes_or_no):
... print(row.person.name, row[yes_or_no]) # could be row(yes_or_no) too
...
Alex No
Bob Yes
Ken No
`` Update_record``
py4web também permite actualizar um único registro que já está na memória usando `` update_record``
>>> row = db(db.person.id == 2).select().first()
>>> row.update_record(name='Curt')
<Row {'id': 2, 'name': 'Curt'}>
`` Update_record`` não deve ser confundido com
>>> row.update(name='Curt')
porque para uma única linha, o método `` update`` atualiza o objeto de linha, mas não o registro de banco de dados, como no case de `` update_record``.
Também é possível alterar os atributos de uma linha (um de cada vez) e, em seguida, chamar `` update_record () `` sem argumentos para salvar as alterações:
>>> row = db(db.person.id > 2).select().first()
>>> row.name = 'Philip'
>>> row.update_record() # saves above change
<Row {'id': 3, 'name': 'Philip'}>
Note, you should avoid using
row.update_record()with no arguments when therowobject contains fields that have anupdateattribute (e.g.,Field('modified_on', update=datetime.datetime.utcnow)). Callingrow.update_record()will retain all of the existing values in therowobject, so any fields withupdateattributes will have no effect in this case. Be particularly mindful of this with tables that includeauth.signature.
O método update_record` está disponível apenas se campo` id` da tabela está incluído no seleto, e` cacheable` não está definido para` True`.
Inserir e atualizar a partir de um dicionário
Um problema comum é composto de precisar inserir ou atualizar registros em uma tabela onde o nome da tabela, o campo para ser atualizado, eo valor para o campo são armazenados em variáveis. Por exemplo: `` tablename``, `` fieldname``, e `` value``.
A inserção pode ser feito usando a seguinte sintaxe:
db[tablename].insert(**{fieldname:value})
A atualização do registro com dado id pode ser feito com:
db(db[tablename]._id == id).update(**{fieldname:value})
Observe que usamos `` table._id`` ao invés de `` table.id``. Desta forma, a consulta funciona mesmo para tabelas com um campo de chave primária com o tipo diferente de “id”.
`` `` First`` e last``
Dado um objecto linhas contendo registos:
rows = db(query).select()
first_row = rows.first()
last_row = rows.last()
são equivalentes às
first_row = rows[0] if len(rows) else None
last_row = rows[-1] if len(rows) else None
Observe, `` primeiro () `` e `` última () `` permitem obter, obviamente, o primeiro e último registro presente em sua consulta, mas isso não significa que esses registros estão indo para ser o primeiro ou o último inserido registros. No case de pretender o primeiro ou último registro inserido em uma determinada tabela não se esqueça de usar `` orderby = db.table_name.id``. Se você esquecer você só vai conseguir o primeiro eo último registro retornado pela consulta, que são muitas vezes em uma ordem aleatória determinada pelo otimizador de consulta backend.
`` `` As_dict`` e as_list``
Fila objecto pode ser serializados em um dicionário normal usando a `` as_dict () `` método e um objecto de linhas pode ser serializados em uma lista de dicionários usando a `` as_list () `` método. aqui estão alguns exemplos:
rows = db(query).select()
rows_list = rows.as_list()
first_row_dict = rows.first().as_dict()
These methods are convenient for passing Rows to generic views and or to store Rows in sessions (Rows objects themselves cannot be serialized because they contain a reference to an open DB connection):
rows = db(query).select()
session.rows = rows # not allowed!
session.rows = rows.as_list() # allowed!
Combinando Rows
Fileiras objectos podem ser combinadas no nível Python. Aqui assumimos:
>>> print(rows1)
person.name
Max
Tim
>>> print(rows2)
person.name
John
Tim
Você pode fazer a união dos registros em dois conjuntos de linhas:
>>> rows3 = rows1 + rows2
>>> print(rows3)
person.name
Max
Tim
John
Tim
Você pode fazer a união dos registros remoção de duplicatas:
>>> rows3 = rows1 | rows2
>>> print(rows3)
person.name
Max
Tim
John
Você pode fazer intersecção dos registros em dois conjuntos de linhas:
>>> rows3 = rows1 & rows2
>>> print(rows3)
person.name
Tim
`` Find``, `` exclude``, `` sort``
Algumas vezes você precisa executar duas seleciona e um contém um subconjunto de um seleto anterior. Neste case, é inútil para acessar o banco de dados novamente. Os `` find``, `` exclude`` e `` objetos sort`` permitem manipular fileiras objeto e gerar outro sem acessar o banco de dados. Mais especificamente: - `` retorna find`` um novo conjunto de linhas filtradas por uma condição e deixa o inalterados originais. - `` retornos exclude`` um novo conjunto de linhas filtrados por uma condição e remove-los das linhas originais. - `` retorna sort`` um novo conjunto de linhas classificadas por uma condição e deixa o inalterados originais.
Todos estes métodos dar um único argumento, uma função que age em cada linha individual.
Aqui está um exemplo de uso:
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> db.person.insert(name='John')
1
>>> db.person.insert(name='Max')
2
>>> db.person.insert(name='Alex')
3
>>> rows = db(db.person).select()
>>> for row in rows.find(lambda row: row.name[0]=='M'):
... print(row.name)
...
Max
>>> len(rows)
3
>>> for row in rows.exclude(lambda row: row.name[0]=='M'):
... print(row.name)
...
Max
>>> len(rows)
2
>>> for row in rows.sort(lambda row: row.name):
... print(row.name)
...
Alex
John
Eles podem ser combinados:
>>> rows = db(db.person).select()
>>> rows = rows.find(lambda row: 'x' in row.name).sort(lambda row: row.name)
>>> for row in rows:
... print(row.name)
...
Alex
Max
Tipo leva um argumento opcional `` reversa = True`` com o significado óbvio.
O método find` tem um argumento` limitby` opcional com a mesma sintaxe e funcionalidade como o conjunto` método SELECT`.
Selects com cache
The select method also takes a cache argument, which defaults to
None. For caching purposes, it should be set to a tuple where the first
element is the cache function with signature (key, callback, expiration)
(for example cache.get assuming cache
is an instance of the py4web cache object), and
the second element is the expiration time in seconds.
No exemplo a seguir, você vê um controlador que armazena em cache um seleto sobre a mesa db.log previamente definido. As buscas reais dados selecionados do banco de dados back-end não mais do que uma vez a cada 60 segundos e armazena o resultado na memória. Se a próxima chamada para este controlador ocorre em menos de 60 segundos desde o último banco de dados IO, ele simplesmente vai buscar os dados anteriores da memória.
def cache_db_select():
logs = db().select(db.log.ALL, cache=(cache.get, 60))
return dict(logs=logs)
O método SELECT` tem um argumento` cacheable` opcional, normalmente definido como False. Quando `` cacheável = True`` o resultante `` Rows`` Serializável mas `` A falta row`` s `` `` update_record`` e métodos delete_record``.
Se você não precisar destes métodos você pode acelerar seleciona um lote, definindo o atributo `` cacheable``:
rows = db(query).select(cacheable=True)
Quando o argumento `` cache`` está definido, mas `` cacheable = False`` (default), apenas os resultados de banco de dados são armazenados em cache, não as linhas reais objeto. Quando o argumento `` cache`` é usado em conjunto com `` cacheável = True`` as linhas inteiras objecto é cache e isso resulta em muito mais rápido cache:
rows = db(query).select(cache=(cache.get, 3600), cacheable=True)
Computed and Virtual fields
Campos computados
Campos DAL podem ter um atributo `` compute``. Esta deve ser uma função (ou lambda) que recebe um objeto Row e retorna um valor para o campo. Quando um novo registo é modificado, incluindo inserções e atualizações, se um valor para o campo não é fornecido, py4web tenta calcular a partir dos outros valores de campo utilizando a função `` compute``. Aqui está um exemplo:
>>> db.define_table('item',
... Field('unit_price', 'double'),
... Field('quantity', 'integer'),
... Field('total_price',
... compute=lambda r: r['unit_price'] * r['quantity']))
<Table item (id, unit_price, quantity, total_price)>
>>> rid = db.item.insert(unit_price=1.99, quantity=5)
>>> db.item[rid]
<Row {'total_price': '9.95', 'unit_price': 1.99, 'id': 1L, 'quantity': 5}>
Notice that the computed value is stored in the db and it is not computed on retrieval, as in the case of virtual fields, described next. Two typical applications of computed fields are:
in wiki applications, to store the processed input wiki text as HTML, to avoid re-processing on every request
for searching, to compute normalized values for a field, to be used for searching.
Computed fields are evaluated in the order in which they are defined in the table definition. A computed field can refer to previously defined computed fields.
Campos virtuais
Campos virtuais também são computados campos (como na subseção anterior), mas eles diferem daquelas porque são * * virtual no sentido de que não são armazenadas no db e eles são calculados a cada vez registros são extraídos do banco de dados. Eles podem ser usados para simplificar o código do usuário sem usar armazenamento adicional, mas eles não podem ser usados para pesquisa.
Campos virtuais novo estilo (experimental)
py4web fornece uma nova e mais fácil maneira de definir campos virtuais e campos virtuais preguiçosos. Esta seção é marcado experimental porque as APIs ainda podem mudar um pouco do que é descrito aqui.
Aqui vamos considerar o mesmo exemplo na subseção anterior. Em particular, considere o seguinte modelo:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
Pode-se definir um `` total_price`` campo virtual como
db.item.total_price = Field.Virtual(lambda row: row.item.unit_price * row.item.quantity)
isto é, simplesmente definindo um novo campo `` total_price`` ser um `` Field.Virtual``. O único argumento do construtor é uma função que recebe uma linha e retorna os valores calculados.
Um campo virtual definido como o descrito acima é calculado automaticamente para todos os registros quando os registros são selecionados:
for row in db(db.item).select():
print(row.total_price)
Também é possível definir campos de métodos que são calculados on-demand, quando chamado. Por exemplo:
db.item.discounted_total = \
Field.Method(lambda row, discount=0.0:
row.item.unit_price * row.item.quantity * (100.0 - discount / 100))
Neste case, `` row.discounted_total`` não é um valor, mas uma função. A função usa os mesmos argumentos que a função passada para o `` construtor Method`` exceto `` row`` que está implícito (pense nisso como `` self`` para objetos).
O campo preguiçoso no exemplo acima permite uma para calcular o valor total para cada `` item``:
for row in db(db.item).select(): print(row.discounted_total())
E também permite passar um `` percentual discount`` opcional (digamos 15%):
for row in db(db.item).select(): print(row.discounted_total(15))
Campos virtuais e de método também podem ser definidos no lugar quando uma tabela é definida:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'),
Field.Virtual('total_price', lambda row: ...),
Field.Method('discounted_total', lambda row, discount=0.0: ...))
Mind that virtual fields do not have the same attributes as regular fields (length, default, required, etc). They do not appear in the list of
db.table.fields.
Campos virtuais velho antigo
A fim de definir um ou mais virtuais campos, você também pode definir uma classe de contêiner, instanciá-lo e vinculá-lo a uma tabela ou a um seleto. Por exemplo, considere a seguinte tabela:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
Pode-se definir um `` total_price`` campo virtual como
class MyVirtualFields:
def total_price(self):
return self.item.unit_price * self.item.quantity
db.item.virtualfields.append(MyVirtualFields())
Observe que cada método da classe que recebe um único argumento (auto) é um novo campo virtual. `` Self`` refere-se a cada linha de uma select. valores de campo são referidos pelo caminho completo como em `` self.item.unit_price``. A tabela está ligada aos campos virtuais anexando uma instância da classe para atributo `` virtualfields`` da tabela.
Campos virtuais também podem acessar campos recursivos como em
db.define_table('item',
Field('unit_price', 'double'))
db.define_table('order_item',
Field('item', 'reference item'),
Field('quantity', 'integer'))
class MyVirtualFields:
def total_price(self):
return self.order_item.item.unit_price * self.order_item.quantity
db.order_item.virtualfields.append(MyVirtualFields())
Observe o acesso de campo recursiva `` self.order_item.item.unit_price`` onde `` self`` é o registro looping.
Eles também podem agir sobre o resultado de um JOIN
rows = db(db.order_item.item == db.item.id).select()
class MyVirtualFields:
def total_price(self):
return self.item.unit_price * self.order_item.quantity
rows.setvirtualfields(order_item=MyVirtualFields())
for row in rows:
print(row.order_item.total_price)
Note como neste case, a sintaxe é diferente. O campo virtual acessa tanto `` self.item.unit_price`` e `` self.order_item.quantity`` que pertencem ao juntar-se selecionar. O campo virtual é anexado para as linhas da tabela usando o método setvirtualfields` do objecto linhas. Este método leva um número arbitrário de argumentos nomeados e pode ser usado para definir vários campos virtuais, definidos em várias classes, e anexá-los a várias tabelas:
class MyVirtualFields1:
def discounted_unit_price(self):
return self.item.unit_price * 0.90
class MyVirtualFields2:
def total_price(self):
return self.item.unit_price * self.order_item.quantity
def discounted_total_price(self):
return self.item.discounted_unit_price * self.order_item.quantity
rows.setvirtualfields(item=MyVirtualFields1(),
order_item=MyVirtualFields2())
for row in rows:
print(row.order_item.discounted_total_price)
Campos virtuais podem ser * lazy* ; tudo que eles precisam fazer é retornar uma função e acessá-lo chamando a função:
db.define_table('item',
Field('unit_price', 'double'),
Field('quantity', 'integer'))
class MyVirtualFields:
def lazy_total_price(self):
def lazy(self=self):
return self.item.unit_price * self.item.quantity
return lazy
db.item.virtualfields.append(MyVirtualFields())
for item in db(db.item).select():
print(item.lazy_total_price())
ou mais curto utilizando uma função lambda:
class MyVirtualFields:
def lazy_total_price(self):
return lambda self=self: self.item.unit_price * self.item.quantity
Joins and Relations
Um para muitos relação
Para ilustrar como implementar um para muitos relação com a DAL, definir outra mesa “coisa” que refere-se à mesa “pessoa” que redefinir aqui:
>>> db.define_table('person',
... Field('name'))
<Table person (id, name)>
>>> db.person.insert(name='Alex')
1
>>> db.person.insert(name='Bob')
2
>>> db.person.insert(name='Carl')
3
>>> db.define_table('thing',
... Field('name'),
... Field('owner_id', 'reference person'))
<Table thing (id, name, owner_id)>
Table “thing” has two fields, the name of the thing and the owner of the
thing. The “owner_id” field is a reference field, it is intended that
the field reference the other table by its id. A reference type can be
specified in two equivalent ways, either:
Field('owner_id', 'reference person') or:
Field('owner_id', db.person).
Este último é sempre convertido para o ex. Eles são equivalentes, exceto no case de tabelas preguiçosos, referências auto ou outros tipos de referências cíclicas onde o ex-notação é a notação só é permitido.
Agora, insira três coisas, duas de propriedade de Alex e um por Bob:
>>> db.thing.insert(name='Boat', owner_id=1)
1
>>> db.thing.insert(name='Chair', owner_id=1)
2
>>> db.thing.insert(name='Shoes', owner_id=2)
3
Você pode selecionar como você fez para qualquer outra tabela:
>>> for row in db(db.thing.owner_id == 1).select():
... print(row.name)
...
Boat
Chair
Porque uma coisa tem uma referência a uma pessoa, uma pessoa pode ter muitas coisas, assim que um registro da tabela pessoa agora adquire uma coisa nova atributo, que é um conjunto, que define as coisas dessa pessoa. Isso permite que um loop sobre todas as pessoas e buscar as suas coisas com facilidade:
>>> for person in db().select(db.person.ALL):
... print(person.name)
... for thing in person.thing.select():
... print(' ', thing.name)
...
Alex
Boat
Chair
Bob
Shoes
Carl
Inner join
Outra forma de conseguir um resultado semelhante é usando uma junção, especificamente um INNER JOIN. executa py4web junta-se automaticamente e de forma transparente quando a consulta liga dois ou mais tabelas como no exemplo a seguir:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Observe que py4web fez uma junção, então as linhas agora contêm dois registros, um de cada mesa, ligados entre si. Porque os dois registros podem ter campos com nomes conflitantes, você precisa especificar a tabela quando se extrai um valor de campo de uma linha. Isto significa que enquanto antes que você poderia fazer:
row.name
e era óbvio que se este era o nome de uma pessoa ou uma coisa, em resultado de uma junção que você tem que ser mais explícito e dizer:
row.person.name
ou:
row.thing.name
Há uma sintaxe alternativa para associações internas:
>>> rows = db(db.person).select(join=db.thing.on(db.person.id == db.thing.owner_id))
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Enquanto a saída é o mesmo, o SQL gerado nos dois cases, pode ser diferente. O último sintaxe remove as ambiguidades possíveis quando a mesma tabela é unidas duas vezes e alias:
db.define_table('thing',
Field('name'),
Field('owner_id1', 'reference person'),
Field('owner_id2', 'reference person'))
rows = db(db.person).select(
join=[db.person.with_alias('owner_id1').on(db.person.id == db.thing.owner_id1),
db.person.with_alias('owner_id2').on(db.person.id == db.thing.owner_id2)])
O valor de `` join`` pode ser lista de `` db.table.on (…) `` para participar.
Left outer join
Observe que Carl não aparecer na lista acima, porque ele não tem as coisas. Se você pretende selecionar sobre as pessoas (se eles têm coisas ou não) e as suas coisas (se tiver algum), então você precisa para realizar um LEFT OUTER JOIN. Isso é feito usando o argumento de “esquerda” da seleção. Aqui está um exemplo:
>>> rows = db().select(db.person.ALL, db.thing.ALL,
... left=db.thing.on(db.person.id == db.thing.owner_id))
>>> for row in rows:
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Carl has None
Where:
left = db.thing.on(...)
é que a esquerda se juntar a consulta. Aqui o argumento de `` db.thing.on`` é a condição necessária para a junção (o mesmo utilizado acima para a junção interna). No case de uma associação à esquerda, é necessário ser explícito sobre quais campos para selecionar.
Multiple esquerda junções podem ser combinados, passando uma lista ou tupla de `` db.mytable.on (…) `` para o parâmetro `` left``.
Agrupamento e contando
Ao fazer junta-se, às vezes você quer agrupar linhas de acordo com certos critérios e contá-los. Por exemplo, contar o número de coisas pertencentes a cada pessoa. py4web permite isso também. Primeiro, você precisa de um operador de contagem. Em segundo lugar, você quer se juntar a tabela a pessoa com o quadro de coisa pelo proprietário. Terceiro, você quer selecionar todas as linhas (pessoa + coisa), agrupá-los por pessoa, e contá-los enquanto agrupamento:
>>> count = db.person.id.count()
>>> for row in db(db.person.id == db.thing.owner_id
... ).select(db.person.name, count, groupby=db.person.name):
... print(row.person.name, row[count])
...
Alex 2
Bob 1
Observe a `` operador count`` (que é incorporado) é usado como um campo. O único problema aqui é em como recuperar a informação. Cada linha contém claramente uma pessoa e a contagem, mas a contagem não é um campo de uma pessoa nem é uma mesa. Então, onde ela vai? Ele vai para o objeto de armazenamento representando o registro com uma chave igual ao próprio expressão de consulta.
O método count` do objeto campo tem um argumento` distinct` opcional. Quando ajustado para `` True`` especifica que apenas os valores distintos de campo em questão estão a ser contadas.
Many to many relation
Nos exemplos anteriores, que permitiram uma coisa para ter um proprietário, mas uma pessoa pode ter muitas coisas. E se barco era propriedade de Alex e Curt? Isso requer uma relação muitos-para-muitos, e é realizada através de uma tabela intermediária que liga uma pessoa a uma coisa através de uma relação de propriedade.
Aqui está como fazê-lo:
>>> db.define_table('person',
... Field('name'))
<Table person (id, name)>
>>> db.person.bulk_insert([dict(name='Alex'), dict(name='Bob'), dict(name='Carl')])
[1, 2, 3]
>>> db.define_table('thing',
... Field('name'))
<Table thing (id, name)>
>>> db.thing.bulk_insert([dict(name='Boat'), dict(name='Chair'), dict(name='Shoes')])
[1, 2, 3]
>>> db.define_table('ownership',
... Field('person', 'reference person'),
... Field('thing', 'reference thing'))
<Table ownership (id, person, thing)>
a relação de propriedade existente pode agora ser reescrita como:
>>> db.ownership.insert(person=1, thing=1) # Alex owns Boat
1
>>> db.ownership.insert(person=1, thing=2) # Alex owns Chair
2
>>> db.ownership.insert(person=2, thing=3) # Bob owns Shoes
3
Agora você pode adicionar a nova relação que Curt co-proprietária Barco:
>>> db.ownership.insert(person=3, thing=1) # Curt owns Boat too
4
Porque agora você tem uma relação de três vias entre as mesas, pode ser conveniente para definir um novo conjunto no qual executar as operações:
>>> persons_and_things = db((db.person.id == db.ownership.person) &
... (db.thing.id == db.ownership.thing))
Agora é fácil para selecionar todas as pessoas e suas coisas da nova Set:
>>> for row in persons_and_things.select():
... print(row.person.name, 'has', row.thing.name)
...
Alex has Boat
Alex has Chair
Bob has Shoes
Curt has Boat
Da mesma forma, você pode procurar por todas as coisas pertencentes a Alex:
>>> for row in persons_and_things(db.person.name == 'Alex').select():
... print(row.thing.name)
...
Boat
Chair
e todos os proprietários de barco:
>>> for row in persons_and_things(db.thing.name == 'Boat').select():
... print(row.person.name)
...
Alex
Curt
A lighter alternative to many-to-many relations is tagging, see the Authorization using Tags chapter. Tagging works even on database backends that do not support JOINs like the Google App Engine NoSQL.
A auto-referência e aliases
É possível definir tabelas com campos que se referem a si mesmos, aqui está um exemplo:
db.define_table('person',
Field('name'),
Field('father_id', 'reference person'),
Field('mother_id', 'reference person'))
Observe que a notação alternativa de usar um objeto de tabela como tipo de campo irá falhar neste case, porque ele usa uma tabela antes de ser definido:
db.define_table('person',
Field('name'),
Field('father_id', db.person), # wrong!
Field('mother_id', db['person'])) # wrong!
Em geral `` db.tablename` e “` referência tablename”`` são tipos de campo equivalentes, mas o último é o único que tem permissão para auto-referências.
Quando uma tabela tem uma auto-referência e você tem que fazer se juntar, por exemplo, para selecionar uma pessoa e seu pai, você precisa de um alias para a tabela. Em SQL um alias é um nome alternativo temporário que você pode usar para fazer referência a uma tabela / coluna em uma consulta (ou outra instrução SQL).
Com py4web você pode fazer um alias para uma tabela usando o método with_alias`. Isso funciona também para expressões, o que significa também para campos desde `` Field`` é derivada de `` Expression``.
Aqui está um exemplo:
>>> fid, mid = db.person.bulk_insert([dict(name='Massimo'), dict(name='Claudia')])
>>> db.person.insert(name='Marco', father_id=fid, mother_id=mid)
3
>>> Father = db.person.with_alias('father')
>>> Mother = db.person.with_alias('mother')
>>> type(Father)
<class 'pydal.objects.Table'>
>>> str(Father)
'person AS father'
>>> rows = db().select(db.person.name, Father.name, Mother.name,
... left=(Father.on(Father.id == db.person.father_id),
... Mother.on(Mother.id == db.person.mother_id)))
>>> for row in rows:
... print(row.person.name, row.father.name, row.mother.name)
...
Massimo None None
Claudia None None
Marco Massimo Claudia
Observe que optámos por fazer uma distinção entre: - “father_id”: o nome do campo usado na “pessoa” mesa; - “pai”: o alias que deseja usar para a tabela referenciada pelo campo acima; esta é comunicada ao banco de dados; - “Pai”: a variável usada por py4web para se referir a esse alias.
A diferença é sutil, e não há nada de errado em usar o mesmo nome para os três:
>>> db.define_table('person',
... Field('name'),
... Field('father', 'reference person'),
... Field('mother', 'reference person'))
<Table person (id, name, father, mother)>
>>> fid, mid = db.person.bulk_insert([dict(name='Massimo'), dict(name='Claudia')])
>>> db.person.insert(name='Marco', father=fid, mother=mid)
3
>>> father = db.person.with_alias('father')
>>> mother = db.person.with_alias('mother')
>>> rows = db().select(db.person.name, father.name, mother.name,
... left=(father.on(father.id==db.person.father),
... mother.on(mother.id==db.person.mother)))
>>> for row in rows:
... print(row.person.name, row.father.name, row.mother.name)
...
Massimo None None
Claudia None None
Marco Massimo Claudia
Mas é importante ter a distinção clara, a fim de construir perguntas corretas.
Outros operadores
py4web tem outros operadores que fornecem uma API para operadores SQL equivalentes de acesso. Vamos definir outra mesa “log” para eventos loja de segurança, sua event_time e gravidade, onde a gravidade é um número inteiro.
>>> db.define_table('log', Field('event'),
... Field('event_time', 'datetime'),
... Field('severity', 'integer'))
<Table log (id, event, event_time, severity)>
Como antes, inserir alguns eventos, a “varredura de portas”, uma “injeção de XSS” e um “login não autorizado”. Por causa do exemplo, você pode registrar eventos com o mesmo event_time mas com diferentes gravidades (1, 2, e 3, respectivamente).
>>> import datetime
>>> now = datetime.datetime.now()
>>> db.log.insert(event='port scan', event_time=now, severity=1)
1
>>> db.log.insert(event='xss injection', event_time=now, severity=2)
2
>>> db.log.insert(event='unauthorized login', event_time=now, severity=3)
3
`` Like``, `` ilike``, `` regexp``, `` startswith``, `` endswith``, `` contains``, `` upper``, `` lower``
Campos tem um `` operador like`` que você pode usar para combinar strings:
>>> for row in db(db.log.event.like('port%')).select():
... print(row.event)
...
port scan
Aqui “porta%” indica uma partida string com “porta”. O personagem por cento sinal, “%”, é um personagem wild-card que significa “qualquer sequência de caracteres”.
O `` operador like`` mapeia para a palavra como em ANSI-SQL. COMO é sensível a maiúsculas na maioria dos bancos de dados, e depende do agrupamento do próprio banco de dados. O método like` é, portanto, case-sensível, mas ele pode ser feito de maiúsculas e minúsculas com
db.mytable.myfield.like('value', case_sensitive=False)
que é o mesmo que usar `` ilike``
db.mytable.myfield.ilike('value')
py4web também fornece alguns atalhos:
db.mytable.myfield.startswith('value')
db.mytable.myfield.endswith('value')
db.mytable.myfield.contains('value')
que são aproximadamente equivalentes, respectivamente, a
db.mytable.myfield.like('value%')
db.mytable.myfield.like('%value')
db.mytable.myfield.like('%value%')
Remember that contains has a special meaning for list:<type>
fields, as discussed in `` Lista: <type> `` e `` contains``.
O método contains` também pode ser passada uma lista de valores e um argumento booleano opcional` all` para procurar registros que contêm todos os valores:
db.mytable.myfield.contains(['value1', 'value2'], all=True)
ou qualquer valor a partir da lista
db.mytable.myfield.contains(['value1', 'value2'], all=False)
Há um também um `` método regexp`` que funciona como o método like` mas permite sintaxe de expressão regular para a expressão look-up. Ele só é suportado pelo MySQL, Oracle, PostgreSQL, SQLite, e MongoDB (com diferente grau de apoio).
O `` upper`` e `` métodos lower`` permitem converter o valor do campo para maiúsculas ou minúsculas, e você também pode combiná-los com o gosto do operador:
>>> for row in db(db.log.event.upper().like('PORT%')).select():
... print(row.event)
...
port scan
`` Year``, `` month``, `` day``, `` hour``, `` minutes``, `` seconds``
A data ea data e hora campos têm `` day``, `` month`` e `` métodos year``. Os campos de data e hora e de tempo têm `` hour``, `` `` minutes`` e métodos seconds``. Aqui está um exemplo:
>>> for row in db(db.log.event_time.year() > 2018).select():
... print(row.event)
...
port scan
xss injection
unauthorized login
`` Belongs``
O operador IN SQL é realizado através do método belongs` que devolve verdadeiro quando o valor do campo pertence ao conjunto especificado (lista ou tuplos):
>>> for row in db(db.log.severity.belongs((1, 2))).select():
... print(row.event)
...
port scan
xss injection
A DAL também permite que um SELECT aninhada como o argumento do operador pertence. A única limitação é que o seleccione aninhada tem de ser um `` _select``, não um `` SELECT``, e apenas um campo tem de ser seleccionada explicitamente, o que define o conjunto.
>>> bad_days = db(db.log.severity == 3)._select(db.log.event_time)
>>> for row in db(db.log.event_time.belongs(bad_days)).select():
... print(row.severity, row.event)
...
1 port scan
2 xss injection
3 unauthorized login
Nos cases em que um seleto aninhada é necessária e o campo look-up é uma referência também podemos usar uma consulta como argumento. Por exemplo:
db.define_table('person', Field('name'))
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
db(db.thing.owner_id.belongs(db.person.name == 'Jonathan')).select()
Neste case, é óbvio que o SELECT aninhada só precisa do campo referenciado pelo campo `` db.thing.owner_id`` por isso não precisa do `` notação mais detalhado _select``.
A selecção pode aninhada também ser usado como insert valor / atualização, mas, neste case, a sintaxe é diferente:
lazy = db(db.person.name == 'Jonathan').nested_select(db.person.id)
db(db.thing.id == 1).update(owner_id = lazy)
Neste case, `` lazy`` é uma expressão aninhada que calcula o `` id`` de pessoa “Jonathan”. As duas linhas resultar em uma consulta SQL única.
`` Sum``, `` avg``, `` min``, `` `` max`` e len``
Anteriormente, você usou o `` operador count`` para contar registros. Da mesma forma, você pode usar o `` operador sum`` para adicionar (soma) os valores de um campo específico de um grupo de registros. Tal como no case de contagem, o resultado de uma soma é recuperado através do objecto de armazenamento:
>>> sum = db.log.severity.sum()
>>> print(db().select(sum).first()[sum])
6
Você também pode usar `` avg``, `` min``, e `` max`` à média, mínimo e valor máximo, respectivamente, para os registros selecionados. Por exemplo:
>>> max = db.log.severity.max()
>>> print(db().select(max).first()[max])
3
`` Len`` calcula o comprimento do valor do campo. Ele é geralmente usado em cordas ou texto campos, mas dependendo do back-end que ainda pode funcionar para outros tipos também (boolean, integer, etc).
>>> for row in db(db.log.event.len() > 13).select():
... print(row.event)
...
unauthorized login
As expressões podem ser combinados para formar expressões mais complexas. Por exemplo, aqui estamos calculando a soma do comprimento das strings de eventos nos logs de mais um:
>>> exp = (db.log.event.len() + 1).sum()
>>> db().select(exp).first()[exp]
43
Substrings
Pode-se construir uma expressão para se referir a uma substring. Por exemplo, podemos agrupar as coisas cujo nome começa com os mesmos três personagens e selecione apenas um de cada grupo:
db(db.thing).select(distinct = db.thing.name[:3])
Os valores por defeito com `` `` coalesce`` e coalesce_zero``
Há momentos em que você precisa para puxar um valor de banco de dados, mas também precisa de valores padrão se o valor para um registro é definido como NULL. Em SQL existe uma função, `` COALESCE``, para isso. py4web tem um método coalesce` equivalente:
>>> db.define_table('sysuser', Field('username'), Field('fullname'))
<Table sysuser (id, username, fullname)>
>>> db.sysuser.insert(username='max', fullname='Max Power')
1
>>> db.sysuser.insert(username='tim', fullname=None)
2
>>> coa = db.sysuser.fullname.coalesce(db.sysuser.username)
>>> for row in db().select(coa):
... print(row[coa])
...
Max Power
tim
Outras vezes você precisa para calcular uma expressão matemática, mas alguns campos têm um valor definido para Nenhum quando deveria ser zero. `` Coalesce_zero`` vem para o resgate por falta Nada a zero na consulta:
>>> db.define_table('sysuser', Field('username'), Field('points'))
<Table sysuser (id, username, points)>
>>> db.sysuser.insert(username='max', points=10)
1
>>> db.sysuser.insert(username='tim', points=None)
2
>>> exp = db.sysuser.points.coalesce_zero().sum()
>>> db().select(exp).first()[exp]
10
>>> type(exp)
<class 'pydal.objects.Expression'>
>>> print(exp)
SUM(COALESCE("sysuser"."points",'0'))
Exportar e importar dados
CSV (uma tabela de cada vez)
Quando um objeto linhas é convertido para uma string é automaticamente serializado na CSV:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> print(rows)
person.id,person.name,thing.id,thing.name,thing.owner_id
1,Alex,1,Boat,1
1,Alex,2,Chair,1
2,Bob,3,Shoes,2
Você pode serializar uma única tabela em formato CSV e armazená-lo em um arquivo “test.csv”:
with open('test.csv', 'wb') as dumpfile:
dumpfile.write(str(db(db.person).select()))
Converting a Rows object into a string produces an encoded binary string
and it’s better to be explicit with the encoding used:
with open('test.csv', 'w', encoding='utf-8', newline='') as dumpfile:
dumpfile.write(str(db(db.person).select()))
Isto é equivalente a
rows = db(db.person).select()
with open('test.csv', 'wb') as dumpfile:
rows.export_to_csv_file(dumpfile)
Você pode ler o arquivo de volta CSV com:
with open('test.csv', 'rb') as dumpfile:
db.person.import_from_csv_file(dumpfile)
Again, you can be explict about the encoding for the exporting file:
rows = db(db.person).select()
with open('test.csv', 'w', encoding='utf-8', newline='') as dumpfile:
rows.export_to_csv_file(dumpfile)
ea importação de um:
with open('test.csv', 'r', encoding='utf-8', newline='') as dumpfile:
db.person.import_from_csv_file(dumpfile)
When importing, py4web looks for the field names in the CSV header. In this example, it finds two columns: “person.id” and “person.name”. It ignores the “person.” prefix, and it ignores the “id” fields. Then all records are appended and assigned new ids.
CSV (todas as tabelas ao mesmo tempo)
Em py4web, você pode backup / restaurar um banco de dados inteiro com dois comandos:
Exportar:
with open('somefile.csv', 'w', encoding='utf-8', newline='') as dumpfile:
db.export_to_csv_file(dumpfile)
Importar:
with open('somefile.csv', 'r', encoding='utf-8', newline='') as dumpfile:
db.import_from_csv_file(dumpfile)
Este mecanismo pode ser utilizado mesmo se a banco de dados de importação é de um tipo diferente do que a banco de dados de exportação.
Os dados são armazenados em “somefile.csv” como um arquivo CSV, onde cada mesa começa com uma linha que indica o nome da tabela, e outra linha com os nomes de campos:
TABLE tablename
field1,field2,field3,...
Duas tabelas são separados por `` r n r n`` (que é duas linhas vazias). As extremidades de arquivos com a linha
END
O arquivo não inclui os arquivos enviados, se estes não são armazenados no banco de dados. Os upload de arquivos armazenados no sistema de arquivos deve ser despejado em separado, um zip dos “uploads” pasta pode ser suficiente na maioria dos cases.
Ao importar, os novos registros serão anexados ao banco de dados se não está vazio. Em geral, os novos registros importados não terão o mesmo ID de registro como os registros originais (salvos), mas py4web irá restaurar referências para que eles não estão quebrados, mesmo que os valores id podem mudar.
Se uma tabela contém um campo chamado `` uuid``, este campo será utilizado para identificar duplicatas. Além disso, se um registro importado tem o mesmo `` uuid`` como um registro existente, o recorde anterior será atualizada.
CSV e sincronização de banco de dados remoto
Considere mais uma vez o seguinte modelo:
db.define_table('person',
Field('name'))
db.define_table('thing',
Field('name'),
Field('owner_id', 'reference person'))
# usage example
if db(db.person).isempty():
nid = db.person.insert(name='Massimo')
db.thing.insert(name='Chair', owner_id=nid)
Cada registro é identificado por um identificador e referenciado por esse id. Se você tem duas cópias do banco de dados usado por instalações py4web distintas, o id é único apenas dentro de cada banco de dados e não através das bases de dados. Este é um problema ao mesclar registros de bancos de dados diferentes.
A fim de fazer registros exclusivamente identificável através de bases de dados, eles devem: - ter um ID único (UUID), - ter uma última modificação para acompanhar o mais recente entre várias cópias, - referência o UUID em vez do id.
Isto pode ser conseguido mudando o modelo acima para:
import datetime
import uuid
now = datetime.datetime.utcnow
db.define_table('person',
Field('uuid', length=64),
Field('modified_on', 'datetime', default=now, update=now),
Field('name'))
db.define_table('thing',
Field('uuid', length=64),
Field('modified_on', 'datetime', default=now, update=now),
Field('name'),
Field('owner_id', length=64))
db.person.uuid.default = db.thing.uuid.default = lambda:str(uuid.uuid4())
db.thing.owner_id.requires = IS_IN_DB(db, 'person.uuid', '%(name)s')
# usage example
if db(db.person).isempty():
nid = str(uuid.uuid4())
db.person.insert(uuid=nid, name='Massimo')
db.thing.insert(name='Chair', owner_id=nid)
Note-se que nas definições da tabela acima, o valor padrão para os dois campos `` uuid`` é definida como uma função de lambda, que retorna um UUID (convertido para uma strings). A função lambda é chamado uma vez para cada registro inserido, garantindo que cada registro recebe um UUID único, mesmo que vários registros são inseridos em uma única transação.
Criar uma ação de controlador para exportar o banco de dados:
from py4web import response
def export():
s = StringIO.StringIO()
db.export_to_csv_file(s)
response.set_header('Content-Type', 'text/csv')
return s.getvalue()
Criar uma ação de controlador para importar uma cópia salva dos outros registros de dados e sincronização:
from yatl.helpers import FORM, INPUT
def import_and_sync():
form = FORM(INPUT(_type='file', _name='data'), INPUT(_type='submit'))
if form.process().accepted:
db.import_from_csv_file(form.vars.data.file, unique=False)
# for every table
for tablename in db.tables:
table = db[tablename]
# for every uuid, delete all but the latest
items = db(table).select(table.id, table.uuid,
orderby=~table.modified_on,
groupby=table.uuid)
for item in items:
db((table.uuid == item.uuid) & (table.id != item.id)).delete()
return dict(form=form)
Opcionalmente, você deve criar um índice manualmente para fazer a busca por uuid mais rápido.
Alternativamente, você pode usar XML-RPC para exportar / importar o arquivo.
Se os registros referência a arquivos enviados, você também precisa exportar / importar o conteúdo da pasta uploads. Observe que os arquivos nele já são rotulados por UUIDs para que você não precisa se preocupar com conflitos de nomes e referências.
HTML e XML (uma tabela de cada vez)
Linhas objetos também têm um método xml` (como ajudantes) que serializa-lo para XML / HTML:
>>> rows = db(db.person.id == db.thing.owner_id).select()
>>> print(rows.xml())
<table>
<thead>
<tr><th>person.id</th><th>person.name</th>
<th>thing.id</th><th>thing.name</th>
<th>thing.owner_id</th>
</tr>
</thead>
<tbody>
<tr class="w2p_odd odd">
<td>1</td><td>Alex</td>
<td>1</td><td>Boat</td>
<td>1</td>
</tr>
<tr class="w2p_even even">
<td>1</td><td>Alex</td>
<td>2</td><td>Chair</td>
<td>1</td>
</tr>
<tr class="w2p_odd odd">
<td>2</td><td>Bob</td>
<td>3</td>
<td>Shoes</td>
<td>2</td>
</tr>
</tbody>
</table>
If you need to serialize the Rows in any other XML format with custom
tags, you can easily do that using the universal TAG XML helper
that we’ll see later and the Python syntax
*<iterable> allowed in function calls:
>>> rows = db(db.person).select()
>>> print(TAG.result(*[TAG.row(*[TAG.field(r[f], _name=f) for f in db.person.fields]) for r in rows]))
<result>
<row><field name="id">1</field><field name="name">Alex</field></row>
<row><field name="id">2</field><field name="name">Bob</field></row>
<row><field name="id">3</field><field name="name">Carl</field></row>
</result>
Aviso
Do not confuse the TAG XML helper used here (see the `` TAG``
chapter) with the Tags method that will be extensively explained
on the Authorization using Tags chapter.
Representação de dados
O método Rows.export_to_csv_file` aceita um argumento de palavra-chave chamada` represent`. Quando `` True`` ele usará as colunas função `` represent`` ao exportar os dados, em vez dos dados brutos.
A função também aceita um argumento de palavra-chave chamada `` colnames`` que deve conter uma lista de nomes de colunas um desejo para exportação. O padrão é todas as colunas.
Ambos `` export_to_csv_file`` e `` import_from_csv_file`` aceitar argumentos de palavra-chave que contam o analisador CSV o formato para salvar / carregar os arquivos: - `` delimiter``: delimitador para separar valores (padrão “”) - `` quotechar : personagem para usar para citar valores String (default para aspas) - `` quoting: sistema de cotação (padrão `` csv.QUOTE_MINIMAL``)
Aqui estão algumas Exemplo de uso:
import csv
rows = db(query).select()
with open('/tmp/test.txt', 'wb') as oufile:
rows.export_to_csv_file(oufile,
delimiter='|',
quotechar='"',
quoting=csv.QUOTE_NONNUMERIC)
O que tornaria algo semelhante a
"hello"|35|"this is the text description"|"2013-03-03"
Para mais informações consulte a documentação oficial do Python
Características avançadas
`` Lista: <type> `` e `` contains``
py4web fornece os seguintes tipos de campos especiais:
list:string
list:integer
list:reference <table>
Eles podem conter listas de cordas, de inteiros e de referências, respectivamente.
No Google App Engine NoSQL `` lista: string`` é mapeado em `` StringListProperty``, os outros dois são mapeados em `` ListProperty (int) ``. Em bancos de dados relacionais são mapeados em campos de texto que contém a lista de itens separados por `` | ``. Por exemplo `` [1, 2, 3] `` é mapeado para `` | 1 | 2 | 3 | ``.
Para listas de corda os itens são escapou de modo que qualquer `` | `` no item é substituído por um `` || ``. De qualquer forma esta é uma representação interna e é transparente para o usuário.
Você pode usar `` lista: string``, por exemplo, da seguinte maneira:
>>> db.define_table('product',
... Field('name'),
... Field('colors', 'list:string'))
<Table product (id, name, colors)>
>>> db.product.colors.requires = IS_IN_SET(('red', 'blue', 'green'))
>>> db.product.insert(name='Toy Car', colors=['red', 'green'])
1
>>> products = db(db.product.colors.contains('red')).select()
>>> for item in products:
... print(item.name, item.colors)
...
Toy Car ['red', 'green']
`` Lista: obras integer`` da mesma forma, mas os itens devem ser inteiros.
Como de costume, os requisitos são aplicadas ao nível das formas, não no nível de `` insert``.
Por `` lista: <type> `` campos de `` contém (valor) `` operador de mapas em uma consulta não trivial que verifica a existência de listas contendo o `` value``. O `` operador contains`` também funciona para regular, `` string`` e `` campos text`` e ele mapeia para um `` LIKE “% value%” ``.
O `` lista: reference`` eo `` contém (valor) `` operador são particularmente úteis para de-normalize muitos-para-muitos relações. Aqui está um exemplo:
>>> db.define_table('tag',
... Field('name'),
... format='%(name)s')
<Table tag (id, name)>
>>> db.define_table('product',
... Field('name'),
... Field('tags', 'list:reference tag'))
<Table product (id, name, tags)>
>>> a = db.tag.insert(name='red')
>>> b = db.tag.insert(name='green')
>>> c = db.tag.insert(name='blue')
>>> db.product.insert(name='Toy Car', tags=[a, b, c])
1
>>> products = db(db.product.tags.contains(b)).select()
>>> for item in products:
... print(item.name, item.tags)
...
Toy Car [1, 2, 3]
>>> for item in products:
... print(item.name, db.product.tags.represent(item.tags))
...
Toy Car red, green, blue
Observe que um `` lista: Campo tag`` referência obter uma restrição padrão
requires = IS_IN_DB(db, db.tag._id, db.tag._format, multiple=True)
que produz um `` / OPTION`` gota-caixa múltipla SELECT formas.
Além disso, observe que este campo recebe um atributo represent` que representa a lista de referências como uma lista separada por vírgulas de referências formatados` padrão. Isto é usado em leitura `` forms``.
Enquanto `` lista: reference`` tem um validador padrão e uma representação padrão, `` lista: integer`` e `` lista: string`` não. Então, esses dois precisam de um `` IS_IN_SET`` ou um `` validador IS_IN_DB`` se você quiser usá-los em formas.
Herança de tabela
É possível criar uma tabela que contém todos os campos de outra tabela. É suficiente para passar a outra tabela no lugar de um campo para `` define_table``. Por exemplo
>>> db.define_table('person', Field('name'), Field('gender'))
<Table person (id, name, gender)>
>>> db.define_table('doctor', db.person, Field('specialization'))
<Table doctor (id, name, gender, specialization)>
Também é possível definir uma tabela fictícia que não está armazenado em um banco de dados, a fim de reutilizá-la em vários outros lugares. Por exemplo:
now = datetime.datetime.utcnow
signature = db.Table(db, 'signature',
Field('is_active', 'boolean', default=True),
Field('created_on', 'datetime', default=now),
Field('created_by', db.auth_user, default=auth.user_id),
Field('modified_on', 'datetime', update=now),
Field('modified_by', db.auth_user, update=auth.user_id))
db.define_table('payment', Field('amount', 'double'), signature)
Este exemplo parte do princípio que a autenticação py4web padrão está activada.
Note que se você usar `` Auth`` py4web já cria uma tal mesa para você:
auth = Auth(db)
db.define_table('payment', Field('amount', 'double'), auth.signature)
Ao usar herança de tabela, se você deseja que a tabela herdar a validadores herdar, certifique-se de definir os validadores de tabela pai antes de definir a tabela herdar.
`` `` Filter_in`` e filter_out``
É possível definir um filtro para cada campo a ser chamada antes de um valor é inserido na banco de dados para esse campo e depois de um valor é recuperado a partir da banco de dados.
Imagine for example that you want to store a serializable Python data structure in a field in the JSON format. Here is how it could be accomplished:
>>> import json
>>> db.define_table('anyobj',
... Field('name'),
... Field('data', 'text'))
<Table anyobj (id, name, data)>
>>> db.anyobj.data.filter_in = lambda obj: json.dumps(obj)
>>> db.anyobj.data.filter_out = lambda txt: json.loads(txt)
>>> myobj = ['hello', 'world', 1, {2: 3}]
>>> aid = db.anyobj.insert(name='myobjname', data=myobj)
>>> row = db.anyobj[aid]
>>> row.data
['hello', 'world', 1, {'2': 3}]
Another way to accomplish the same is by using a Field of type
SQLCustomType, as discussed in Personalizados `` tipos Field``.
retornos de chamada no registro de inserção, exclusão e atualização
PY4WEB fornece um mecanismo para registrar retornos de chamada para ser chamado antes e / ou após a inserção, atualização e exclusão de registros.
Cada tabela armazena seis listas de chamadas de retorno:
db.mytable._before_insert
db.mytable._after_insert
db.mytable._before_update
db.mytable._after_update
db.mytable._before_delete
db.mytable._after_delete
Você pode registrar uma função de retorno de chamada, acrescentando-o à lista correspondente. A ressalva é que, dependendo da funcionalidade, o retorno tem assinatura diferente.
This is best explained by examples.
>>> db.define_table('person', Field('name'))
<Table person (id, name)>
>>> def pprint(callback, *args):
... print("%s%s" % (callback, args))
...
>>> db.person._before_insert.append(lambda f: pprint('before_insert', f))
>>> db.person._after_insert.append(lambda f, i: pprint('after_insert', f, i))
>>> db.person.insert(name='John')
before_insert(<OpRow {'name': 'John'}>,)
after_insert(<OpRow {'name': 'John'}>, 1)
1
>>> db.person._before_update.append(lambda s, f: pprint('before_update', s, f))
>>> db.person._after_update.append(lambda s, f: pprint('after_update', s, f))
>>> db(db.person.id == 1).update(name='Tim')
before_update(<Set ("person"."id" = 1)>, <OpRow {'name': 'Tim'}>)
after_update(<Set ("person"."id" = 1)>, <OpRow {'name': 'Tim'}>)
1
>>> db.person._before_delete.append(lambda s: pprint('before_delete', s))
>>> db.person._after_delete.append(lambda s: pprint('after_delete', s))
>>> db(db.person.id == 1).delete()
before_delete(<Set ("person"."id" = 1)>,)
after_delete(<Set ("person"."id" = 1)>,)
1
Como você pode ver: - `` f`` é passado o objeto `` OpRow`` com os dados para inserção ou atualização. - `` i`` é passado o id do registro recém-inserido. - `` s`` é passado o objeto `` Set`` usado para atualizar ou excluir. `` OpRow`` é um objeto auxiliar especializada em armazenamento (campo, valor) pares, você pode pensar nisso como um dicionário normal que você pode usar até mesmo com a sintaxe da notação atributo (que é `` f.name`` e `` f [ “nome”] `` são equivalentes).
Os valores de retorno destes callback deve ser `` None`` ou `` False``. Se qualquer um dos `` _antes_ * `` retorno de chamada retorna um `` valor True`` ele irá abortar a / update / operação de exclusão real de inserção.
Algumas vezes uma chamada de retorno pode precisar executar uma atualização na mesma ou em uma tabela diferente e se quer evitar disparar outras chamadas de retorno, o que poderia causar um loop infinito.
Para este efeito, há os objetos `` Set`` tem um método update_naive` que funciona como` update` mas ignora antes e depois de retornos de chamada.
Cascades no banco de dados
Database schema can define relationships which trigger deletions of related records, known as cascading. The DAL is not informed when a record is deleted due to a cascade. So no *_delete callback will ever be called as consequence of a cascade-deletion.
versionamento recorde
É possível pedir py4web para salvar cada cópia de um registro quando o registro é modificado individualmente. Existem diferentes maneiras de fazer isso e que pode ser feito para todas as tabelas ao mesmo tempo usando a sintaxe:
auth.enable_record_versioning(db)
isso requer `` Auth``. Ele também pode ser feito para cada mesa, como discutido abaixo.
Considere a seguinte tabela:
db.define_table('stored_item',
Field('name'),
Field('quantity', 'integer'),
Field('is_active', 'boolean',
writable=False, readable=False, default=True))
Observe o campo booleano oculto chamado `` is_active`` e padronizando para True.
Podemos dizer py4web para criar uma nova tabela (no mesmo ou em outro banco de dados) e armazenar todas as versões anteriores de cada registro na tabela, quando modificado.
Isso é feito da seguinte maneira:
db.stored_item._enable_record_versioning()
ou em uma sintaxe mais detalhado:
db.stored_item._enable_record_versioning(archive_db=db,
archive_name='stored_item_archive',
current_record='current_record',
is_active='is_active')
O `` archive_db = db`` diz py4web para armazenar a tabela de arquivo no mesmo banco de dados como o `` tabela stored_item``. O `` archive_name`` define o nome para a tabela de arquivo. A tabela de arquivo tem os mesmos campos como a tabela original `` stored_item`` exceto que campos exclusivos não são mais exclusivo (porque ele precisa para armazenar várias versões) e tem um campo extra que nome é especificado por `` current_record`` e que é uma referência para o registo atual na tabela `` stored_item``.
Quando os registros são excluídos, eles não são realmente excluídos. Um registro excluído é copiado na tabela `` stored_item_archive`` (como quando ele é modificado) e do campo `` is_active`` é definido como False. Ao permitir gravar versões conjuntos py4web um `` common_filter`` nesta tabela que esconde todos os registros na tabela `` stored_item`` onde o campo `` is_active`` é definida como falsa. O parâmetro `` is_active`` no método _enable_record_versioning` permite especificar o nome do campo usado pelo` common_filter` para determinar se o campo foi excluído ou não.
filtros comuns
Um filtro comum é uma generalização da ideia multi-tenancy acima. Ele fornece uma maneira fácil de evitar a repetição da mesma consulta. Considere, por exemplo, a tabela a seguir:
db.define_table('blog_post',
Field('subject'),
Field('post_text', 'text'),
Field('is_public', 'boolean'),
common_filter = lambda query: db.blog_post.is_public == True)
Qualquer select, DELETE ou UPDATE nesta tabela, vai incluir posts única públicos. O atributo também pode ser modificado em tempo de execução:
db.blog_post._common_filter = lambda query: ...
Ela serve tanto como uma forma de evitar a repetição do “db.blog_post.is_public == True” frase em cada blog pesquisa post, e também como uma melhoria de segurança, que o impede de esquecer para não permitir a visualização de mensagens não-públicas.
No case de você realmente quer itens deixados de fora pelo filtro comum (por exemplo, permitindo que o administrador para ver mensagens não-públicas), você pode remover o filtro:
db.blog_post._common_filter = None
ou ignorá-lo:
db(query, ignore_common_filters=True)
Note-se que common_filters são ignorados pela interface AppAdmin.
Personalizados `` tipos Field``
Além de usar o `` filter_in`` e `` filter_out``, é possível definir novos tipos de campos / personalizados. Por exemplo, suponha que você deseja definir um tipo personalizado para armazenar um endereço IP:
>>> def ip2int(sv):
... "Convert an IPV4 to an integer."
... sp = sv.split('.'); assert len(sp) == 4 # IPV4 only
... iip = 0
... for i in map(int, sp): iip = (iip<<8) + i
... return iip
...
>>> def int2ip(iv):
... "Convert an integer to an IPV4."
... assert iv > 0
... iv = (iv,); ov = []
... for i in range(3):
... iv = divmod(iv[0], 256)
... ov.insert(0, iv[1])
... ov.insert(0, iv[0])
... return '.'.join(map(str, ov))
...
>>> from pydal import SQLCustomType
>>> ipv4 = SQLCustomType(type='string', native='integer',
... encoder=lambda x : str(ip2int(x)), decoder=int2ip)
>>> db.define_table('website',
... Field('name'),
... Field('ipaddr', type=ipv4))
<Table website (id, name, ipaddr)>
>>> db.website.insert(name='wikipedia', ipaddr='91.198.174.192')
1
>>> db.website.insert(name='google', ipaddr='172.217.11.174')
2
>>> db.website.insert(name='youtube', ipaddr='74.125.65.91')
3
>>> db.website.insert(name='github', ipaddr='207.97.227.239')
4
>>> rows = db(db.website.ipaddr > '100.0.0.0').select(orderby=~db.website.ipaddr)
>>> for row in rows:
... print(row.name, row.ipaddr)
...
github 207.97.227.239
google 172.217.11.174
`` SQLCustomType`` é uma fábrica tipo de campo. Seu argumento `` type`` deve ser um dos tipos py4web padrão. Diz py4web como tratar os valores de campo no nível py4web. `` Native`` é o tipo do campo, tanto quanto a banco de dados está em causa. nomes permitidos dependem do mecanismo de banco de dados. `` Encoder`` é uma transformação opcional função aplicada quando os dados são armazenados e `` decoder`` é a função de transformação inversa opcional.
This feature is marked as experimental because can make your code not portable across database engines.
Ele não funciona no Google App Engine NoSQL.
Usando DAL sem definir tabelas
A DAL pode ser usado a partir de qualquer programa Python simplesmente fazendo isso:
from pydal import DAL, Field
db = DAL('sqlite://storage.sqlite', folder='path/to/app/databases')
ou seja, importar a DAL, conexão e especificar a pasta que contém os arquivos .table (a pasta app / bancos de dados).
Para acessar os dados e seus atributos ainda temos que definir todas as tabelas que vão de acesso com `` db.define_table``.
Se nós apenas precisam de acesso aos dados, mas não para os atributos da tabela py4web, nós fugir sem re-definir as tabelas, mas simplesmente pedindo py4web para ler as informações necessárias a partir dos metadados nos ficheiros .table:
from py4web import DAL, Field
db = DAL('sqlite://storage.sqlite', folder='path/to/app/databases', auto_import=True)
Isso nos permite acessar qualquer db.table sem necessidade de re definir-lo.
Transação distribuída
No momento da escrita deste recurso só é suportado pelo PostgreSQL, MySQL e Firebird, uma vez que expõem API para commits de duas fases.
Supondo que você tenha dois (ou mais) conexões com bancos de dados PostgreSQL distintas, por exemplo:
db_a = DAL('postgres://...')
db_b = DAL('postgres://...')
Em seus modelos ou controladores, você pode cometê-los simultaneamente com:
DAL.distributed_transaction_commit(db_a, db_b)
Em case de falha, esta função desfaz e levanta uma `` Exception``.
Em controladores, quando uma ação retornos, se você tiver duas ligações distintas e você não chamar a função acima, py4web compromete-los separadamente. Isto significa que há uma possibilidade de que um dos commits sucede e uma falha. A transação distribuída impede que isso aconteça.
Copiar dados de um para outro db
Considere a situação em que você estiver usando o seguinte banco de dados:
db = DAL('sqlite://storage.sqlite')
e você deseja mover para outro banco de dados usando uma seqüência de conexão diferente:
db = DAL('postgres://username:password@localhost/mydb')
Antes de mudar, você quer mover os dados e reconstruir todos os metadados para o novo banco de dados. Assumimos o novo banco de dados a existir, mas nós também assumir que é vazio.
Pegadinhas
Nota sobre novo DAL e adaptadores
O código fonte do Banco de Dados Camada de Abstração foi completamente reescrito em 2010. Enquanto ele permanece compatível com versões anteriores, a reescrita tornou mais modular e mais fácil de estender. Aqui nós explicamos a lógica principal.
The module “dal.py” defines, among other, the following classes.
ConnectionPool
BaseAdapter extends ConnectionPool
Row
DAL
Reference
Table
Expression
Field
Query
Set
Rows
Seu uso tem sido explicado nas seções anteriores, exceto para `` BaseAdapter``. Quando os métodos de um `` Table`` ou `` necessidade objeto Set`` para se comunicar com o banco de dados que confiam aos métodos do adaptador a tarefa para gerar o SQL e ou a chamada de função.
Por exemplo:
db.mytable.insert(myfield='myvalue')
chamadas
Table.insert(myfield='myvalue')
que delega o adaptador de voltar:
db._adapter.insert(db.mytable, db.mytable._listify(dict(myfield='myvalue')))
Aqui `` convertidos db.mytable._listify`` o dict dos argumentos em uma lista de `` (campo, valor) `` e chama o método insert` do` adapter`. `` Db._adapter`` faz mais ou menos o seguinte:
query = db._adapter._insert(db.mytable, list_of_fields)
db._adapter.execute(query)
onde a primeira linha constrói a consulta e o segundo executa.
`` BaseAdapter`` define a interface para todas as placas.
pyDAL at the moment of writing this book, contains the following adapters:
SQLiteAdapter extends BaseAdapter
JDBCSQLiteAdapter extends SQLiteAdapter
MySQLAdapter extends BaseAdapter
PostgreSQLAdapter extends BaseAdapter
JDBCPostgreSQLAdapter extends PostgreSQLAdapter
OracleAdapter extends BaseAdapter
MSSQLAdapter extends BaseAdapter
MSSQL2Adapter extends MSSQLAdapter
MSSQL3Adapter extends MSSQLAdapter
MSSQL4Adapter extends MSSQLAdapter
FireBirdAdapter extends BaseAdapter
FireBirdEmbeddedAdapter extends FireBirdAdapter
InformixAdapter extends BaseAdapter
DB2Adapter extends BaseAdapter
IngresAdapter extends BaseAdapter
IngresUnicodeAdapter extends IngresAdapter
GoogleSQLAdapter extends MySQLAdapter
NoSQLAdapter extends BaseAdapter
GoogleDatastoreAdapter extends NoSQLAdapter
CubridAdapter extends MySQLAdapter (experimental)
TeradataAdapter extends DB2Adapter (experimental)
SAPDBAdapter extends BaseAdapter (experimental)
CouchDBAdapter extends NoSQLAdapter (experimental)
IMAPAdapter extends NoSQLAdapter (experimental)
MongoDBAdapter extends NoSQLAdapter (experimental)
VerticaAdapter extends MSSQLAdapter (experimental)
SybaseAdapter extends MSSQLAdapter (experimental)
que substituir o comportamento dos `` BaseAdapter``.
Cada adaptador tem mais ou menos a seguinte estrutura:
class MySQLAdapter(BaseAdapter):
# specify a driver to use
driver = globals().get('pymysql', None)
# map py4web types into database types
types = {
'boolean': 'CHAR(1)',
'string': 'VARCHAR(%(length)s)',
'text': 'LONGTEXT',
...
}
# connect to the database using driver
def __init__(self, db, uri, pool_size=0, folder=None, db_codec ='UTF-8',
credential_decoder=lambda x:x, driver_args={},
adapter_args={}):
# parse uri string and store parameters in driver_args
...
# define a connection function
def connect(driver_args=driver_args):
return self.driver.connect(**driver_args)
# place it in the pool
self.pool_connection(connect)
# set optional parameters (after connection)
self.execute('SET FOREIGN_KEY_CHECKS=1;')
self.execute("SET sql_mode='NO_BACKSLASH_ESCAPES';")
# override BaseAdapter methods as needed
def lastrowid(self, table):
self.execute('select last_insert_id();')
return int(self.cursor.fetchone()[0])
Olhando para os vários adaptadores como exemplo deve ser fácil de escrever novos.
Quando `` db`` exemplo é criado:
db = DAL('mysql://...')
the prefix in the uri string defines the adapter. The mapping is defined in the following dictionary also in “dal.py”:
couchdb |
pydal.adapters.couchdb.CouchDB |
cubrid |
pydal.adapters.mysql.Cubrid |
db2:ibm_db_dbi |
pydal.adapters.db2.DB2IBM |
db2:pyodbc |
pydal.adapters.db2.DB2Pyodbc |
firebird |
pydal.adapters.firebird.FireBird |
firebird_embedded |
pydal.adapters.firebird.FireBirdEmbedded |
google:MySQLdb |
pydal.adapters.google.GoogleMySQL |
google:datastore |
pydal.adapters.google.GoogleDatastore |
google:datastore+ndb |
pydal.adapters.google.GoogleDatastore |
google:psycopg2 |
pydal.adapters.google.GooglePostgres |
google:sql |
pydal.adapters.google.GoogleSQL |
informix |
pydal.adapters.informix.Informix |
informix-se |
pydal.adapters.informix.InformixSE |
ingres |
pydal.adapters.ingres.Ingres |
ingresu |
pydal.adapters.ingres.IngresUnicode |
pydal.adapters.postgres.JDBCPostgre |
|
pydal.adapters.sqlite.JDBCSQLite |
|
pydal.adapters.sqlite.JDBCSQLite |
|
mongodb |
pydal.adapters.mongo.Mongo |
mssql |
pydal.adapters.mssql.MSSQL1 |
mssql2 |
pydal.adapters.mssql.MSSQL1N |
mssql3 |
pydal.adapters.mssql.MSSQL3 |
mssql3n |
pydal.adapters.mssql.MSSQL3N |
mssql4 |
pydal.adapters.mssql.MSSQL4 |
mssql4n |
pydal.adapters.mssql.MSSQL4N |
mssqln |
pydal.adapters.mssql.MSSQL1N |
mysql |
pydal.adapters.mysql.MySQL |
oracle |
pydal.adapters.oracle.Oracle |
postgres |
pydal.adapters.postgres.Postgre |
postgres2 |
pydal.adapters.postgres.PostgreNew |
postgres2:psycopg2 |
pydal.adapters.postgres.PostgrePsycoNew |
postgres3 |
pydal.adapters.postgres.PostgreBoolean |
postgres3:psycopg2 |
pydal.adapters.postgres.PostgrePsycoBoolean |
postgres:psycopg2 |
pydal.adapters.postgres.PostgrePsyco |
pytds |
pydal.adapters.mssql.PyTDS |
sapdb |
pydal.adapters.sap.SAPDB |
spatialite |
pydal.adapters.sqlite.Spatialite |
spatialite:memory |
pydal.adapters.sqlite.Spatialite |
sqlite |
pydal.adapters.sqlite.SQLite |
sqlite:memory |
pydal.adapters.sqlite.SQLite |
sybase |
pydal.adapters.mssql.Sybase |
teradata |
pydal.adapters.teradata.Teradata |
vertica |
pydal.adapters.mssql.Vertica |
the uri string is then parsed in more detail by the adapter itself. An updated list of adapters can be obtained as dictionary with
For any adapter you can replace the driver with a different one globally (not thread safe):
import MySQLdb as mysqldb
from pydal.adapters.mysql import SQLAdapter
SQLAdapter.driver = mysqldb
isto é `` mysqldb`` tem de ser * que * módulo com um método .Connect (). Você pode especificar argumentos motorista opcionais e argumentos adaptador:
db = DAL(..., driver_args={}, adapter_args={})
For recognized adapters you can also simply specify the name in the
adapter_args:
from pydal.adapters.mysql import MySQL
assert "mysqldv" in MySQL.drivers
db = DAL(..., driver_args={}, adapter_args={"driver": "mysqldb"})
SQLite
SQLite does not support dropping and altering columns. That means that
py4web migrations will work up to a point. If you delete a field from a
table, the column will remain in the database but will be invisible to
py4web. If you decide to reinstate the column, py4web will try re-create
it and fail. In this case you must set fake_migrate=True so that
metadata is rebuilt without attempting to add the column again. Also,
for the same reason, SQLite is not aware of any change of column
type. If you insert a number in a string field, it will be stored as
string. If you later change the model and replace the type “string” with
type “integer”, SQLite will continue to keep the number as a string and
this may cause problem when you try to extract the data.
SQLite não tem um tipo booleano. py4web mapeia internamente booleans para uma strings de 1 carácter, com ‘T’ e ‘F’ representar Verdadeiro e Falso. A DAL lida com isso completamente; a abstração de um verdadeiro valor booleano funciona bem. Mas se você estiver atualizando a tabela SQLite com o SQL diretamente, estar ciente da implementação py4web, e evitar o uso de 0 e 1 valores.
MySQL
MySQL does not support multiple ALTER TABLE within a single transaction.
This means that any migration process is broken into multiple commits.
If something happens that causes a failure it is possible to break a
migration (the py4web metadata are no longer in sync with the actual
table structure in the database). This is unfortunate but it can be
prevented (migrate one table at the time) or it can be fixed in the
aftermath (revert the py4web model to what corresponds to the table
structure in database, set fake_migrate=True and after the metadata
has been rebuilt, set fake_migrate=False and migrate the table
again).
Google SQL
Google SQL has the same problems as MySQL and more. In particular table
metadata itself must be stored in the database in a table that is not
migrated by py4web. This is because Google App Engine has a read-only
file system. PY4WEB migrations in Google SQL combined with the MySQL
issue described above can result in metadata corruption. Again, this can
be prevented (by migrating the table at once and then setting
migrate=False so that the metadata table is not accessed any more) or it
can fixed in the aftermath (by accessing the database using the Google
dashboard and deleting any corrupted entry from the table called
py4web_filesystem.
MSSQL (Microsoft SQL Server)
não MSSQL <2012 não suporta o SQL OFFSET palavra-chave. Portanto, o banco de dados não pode fazer a paginação. Ao fazer um `` limitby = (a, b) `` py4web vai buscar a primeira `` a + b`` linhas e descartar o primeiro `` a``. Isto pode resultar numa sobrecarga considerável quando comparado com outros bancos de dados. Se você estiver usando MSSQL> = 2005, o prefixo recomendado para uso é `` mssql3: // `` que fornece um método para evitar o problema de buscar todo o conjunto de resultados não-paginado. Se você estiver em MSSQL> = 2012, use `` mssql4: // `` que usa o `` OFFSET … ROWS … FETCH PRÓXIMO … ROWS ONLY`` construção para apoiar a paginação nativamente, sem sucessos de desempenho como outros backends. O `` mssql: // `` uri também reforça (por razões históricas) o uso de `` colunas text``, que são superseeded em versões mais recentes (a partir de 2005) por `` varchar (max) . `` Mssql3: // `` e `` mssql4: // `` deve ser usado se você não quer enfrentar algumas limitações do - oficialmente obsoleto - `` colunas text.
MSSQL tem problemas com referências circulares em tabelas que têm onDelete CASCADE. Este é um bug MSSQL e você trabalhar em torno dele, definindo o atributo onDelete para todos os campos de referência a “nenhuma acção”. Você também pode fazê-lo uma vez por todas, antes de definir tabelas:
db = DAL('mssql://....')
for key in db._adapter.types:
if ' ON DELETE %(on_delete_action)s' in db._adapter.types[key]:
db._adapter.types[key] = db._adapter.types[key].replace('%(on_delete_action)s', 'NO ACTION')
MSSQL também tem problemas com argumentos passados para a palavra-chave DISTINCT e, portanto Enquanto isso funciona,
db(query).select(distinct=True)
isso não faz
db(query).select(distinct=db.mytable.myfield)
Oráculo
A Oracle também não suporta a paginação. Ele não suporta nem a OFFSET nem as palavras-chave limite. PY4WEB alcança a paginação, traduzindo um `` db (…). Select (limitby = (a, b)) `` em um complexo de três vias SELECT aninhada (como sugerido por documentação oficial Oracle). Isso funciona para simples escolha, mas pode quebrar para seleciona complexos envolvendo campos e ou junta alias.
Google NoSQL (Datastore)
Google NoSQL (Datastore) não permite que se junta, deixou junta, agregados, expressão ou envolvendo mais de uma tabela, o ‘como’ pesquisas operador em campos “texto”.
As transações são limitados e não fornecida automaticamente pelo py4web (você precisa usar a API do Google `` run_in_transaction`` que você pode procurar na documentação do Google App Engine online).
O Google também limita o número de registros que você pode recuperar em cada uma consulta (1000, no momento da escrita). No Google armazenamento de dados IDs de registro são inteiro, mas eles não são seqüenciais. Enquanto em SQL “lista: string” tipo é mapeado em um tipo de “texto”, no Google Datastore é mapeado em um `` ListStringProperty``. Da mesma forma “lista: número inteiro” e “lista: referência” são mapeados para `` ListProperty``. Isso faz buscas por conteúdo dentro desses campos tipos mais eficientes no Google NoSQL que em bancos de dados SQL.